Web Mining — анализ использования веб-ресурсов. Построение моделей
В предыдущей статье "Web Mining: анализ использования веб-ресурсов, обработка веб-лога" было рассказано о том, как устроен веб-лог: какие поля он включает и чем они могут быть полезны. Также в ней рассмотрена предобработка веб-данных, описание которой сопровождалось примером, где мы использовали данные из веб-лога за март 2010 года.
В этой статье продолжим рассматривать взятый пример и расскажем о том, что же делать дальше с полученными после предобработки данными.
Закончив предобработку, уже можно подвести статистику по некоторым показателям и ответить на важные вопросы, касающиеся функционирования сайта. Рассмотрим подробнее.
Какая страница чаще всего является точкой входа на сайт?
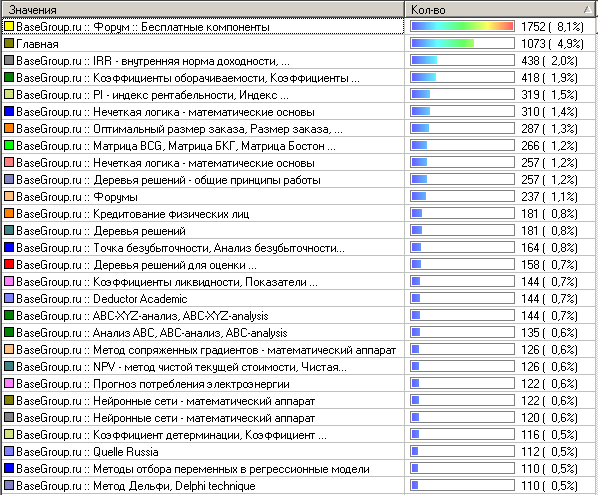
Для этого необходимо упорядочить записи в первую очередь по ID-сессии, во вторую – по временному штампу. Затем сгруппировать данные по ID-сессии, в качестве факта назначив адрес запрошенной страницы (выбрать первую запись). Далее достаточно просто просмотреть статистику и выявить частые точки захода на сайт. Её фрагмент (страницы, с которых чаще всего осуществлялся вход на сайт) представлен на рисунке 1. Наибольшие доли входа на сайт приходятся на страницу форума "бесплатные компоненты" (8,1%) и на главную (4,9%).
Главная страница предусмотрена в качестве естественной точки входа на сайт. По данной статистике можно говорить, что она таковой и является. Но стоит поискать причины, почему она занимает второе место, а не первое.
Проделав аналогичные операции, можно найти и страницы, с которых пользователь ушел с сайта. Наибольшая доля пришлась на те же страницы 7,1% и 3,5% соответственно. Но если обратить внимание, то можно заметить, что более 10% страниц ухода приходится на статьи из раздела "Научная библиотека". Скорее всего, пользователь нашел нужный ему теоретический материал, ознакомился с ним и покинул сайт.
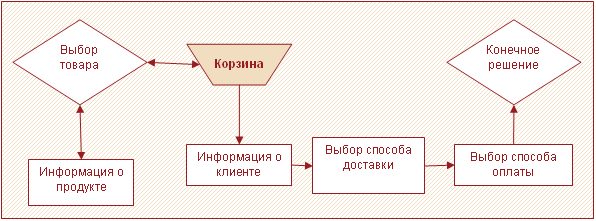
При анализе использования ресурсов интернет-магазина особо следует обращать внимание на то, в какой момент пользователь ушел с портала. На рисунке 2 показаны типичные направления, по которым, как правило, проходит посетитель электронного магазина. После того как товары выбраны, покупатель переходит на страницу, где уточняется информация о нем, затем к выбору способа доставки и способа оплаты. Если посетители постоянно покидают сайт, например, на этапе выбора способа оплаты, то, возможно, их по каким-то причинам не устраивают предложенные варианты.
Вернемся к примеру. Узнать, с каких сайтов было прислано больше всего пользователей, также не составляет труда. Достаточно просмотреть статистику среди направляющих сайтов. В нашем примере за март месяц лидером стал сайт "soft.mail.ru", на долю которого пришлось 0,4% пользователей.
При заданных условия формирования сессии получились следующие усредненные результаты:
- просмотрено пользователем страниц за сессию – 4;
- продолжительность сессии – 15 минут.
Теперь рассмотрим, как же можно применить алгоритмы Data Mining для анализа использования веб-ресурсов.
Кластеризация
В рамках анализа деятельности электронного магазина проводят сегментацию посетителей по их предпочтениям. Для этого применяются различные алгоритмы кластеризации. Рассматриваемый в примере сайт не является таким ресурсом, но все же проверим, к чему приведет попытка выделить кластеры.
В качестве входных полей выберем количество просмотренных страниц и продолжительность сессии. Попробуем обнаружить аномальные сессии. Для этого применим алгоритм k-means, задав фиксированное число кластеров – 2. Если аномалии присутствуют, то они будут сгруппированы отдельно, и доля таких записей будет мала. Общая статистика (профили) получившихся кластеров изображена на рисунке 3.
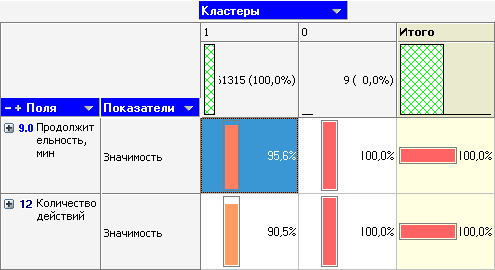
Значимость показывает степень влияния каждого поля на формирование кластера. Из рисунка 3 видно, что для "продолжительности сессии" и "количества действий" этот показатель принимает высокие значения (более 90%).
Результат кластеризации можно проинтерпретировать следующим образом.
Кластер 0 включает в себя всего 9 сессий с высокими показателями средней продолжительности (8115 минут) и количеством просмотренных страниц (2861).
Сессии, попавшие в него, имеют довольно подозрительные показатели и их можно исключить из набора данных как аномалии.
Кластер 1 включает 61315 сессий. Средняя продолжительность сессии – 14 минут, среднее количество просмотренных страниц – 4.
Теперь применим алгоритм кластеризации CLOPE, который был описан в статье "Кластеризация категорийных данных: масштабируемый алгоритм CLOPE".
Он отлично подходит для кластеризации больших массивов категорийных данных.
В качестве транзакции положим ID сессии, а элементом назначим ресурс. Коэффициент отталкивания зададим равным 2. Также ограничим максимальное число кластеров, установив значение 20.
После работы алгоритма получилось 20 кластеров. Общая статистика по всем ним представлена на рисунке 4.

В первую очередь внимание привлекает кластер 8, так как он содержит огромное количество страниц – 119690, и не представляет практического интереса. Сгруппированные в нем ресурсы просто не попали в другие места.
Мощность остальных кластеров изменяется в диапазоне от 1 до 23.
Рассмотрим кластер 17. Статистика о страницах, вошедших в него, приведена в таблице 1.
Таблица 1 – Страницы кластера 17
| Ресурс (адрес или заголовок) | Количество |
|---|---|
| /material/articles/neural/ | 122 |
| BaseGroup.ru :: Метод сопряженных градиентов – ... | 169 |
| BaseGroup.ru :: Метод сопряженных градиентов – математический аппарат | 876 |
| BaseGroup.ru :: Нейронные сети – математический аппарат | 1024 |
Из названий страниц видно, что существуют такие сессии, когда посетители просматривают статьи о методе сопряженных градиентов и нейронных сетях. Подобным образом можно проинтерпретировать и другие кластеры. Как же можно использовать полученный результат?
Предположим, что посетитель зашел на сайт и стал открывать некоторые страницы. В режиме on-line это легко отслеживается, и можно рассчитать, к какому кластеру он ближе. Допустим, что его поведение было приписано к некоторому кластеру, тогда можно этому посетителю предложить просмотреть и остальные страницы из данного кластера. В течение сессии пользователь может быть классифицирован к разным кластерам, и каждый раз ему будут предлагаться новые страницы.
Также информация о принадлежности в тот или иной момент времени к кластеру может заноситься к анкетным данным пользователя (например, если на портале предусмотрена регистрация). Далее можно разделить получившиеся группы по уровню приоритета. Скажем, кластеры, которые содержат страницы, связанные с непосредственной покупкой товара, будут иметь больший приоритет, чем те, в которых страницы содержат информацию о товаре. Таким образом, можно оценить, насколько важен на данный момент тот или иной посетитель: как близко он находится к кластерам с наивысшим приоритетом, тем самым предпринять определенные меры для удержания потенциального клиента. Также можно отследить динамику движения пользователя из одного кластера в другой.
Далее решим задачу ассоциации.
Ассоциация
В зависимости от степени посещаемости портала в качестве транзакции для формирования правил может быть либо ID-пользователя (например, в случае, когда посещаемость небольшая), либо ID-сессии.
В примере рассмотрим оба случая.
Зададим в качестве транзакции ID-пользователя. На рисунке 5 представлены выявленные 11 правил.
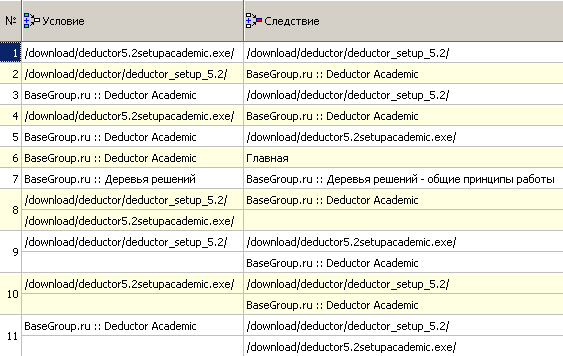
Вследствие правил 5, 9 и 11 есть путь к файлу "deductor5.2setupacademic.exe", который выложен на сайте. Их условия показывают страницы, с которых они переходят к скачиванию этого файла, т.е. если пользователь открыл страницу "Deductor Academic", то, скорее всего, он скачает и установочный файл.
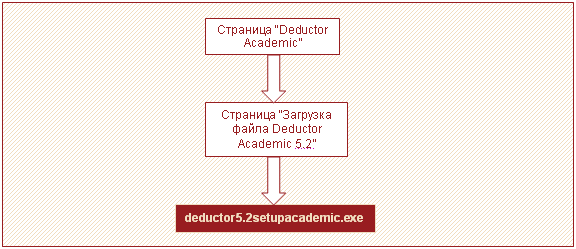
Из правил 9 – 11 можно сделать вывод, что пользователи часто проходят по пути, изображенном на рисунке 6. Данная последовательность страниц к установочному файлу была предусмотрена разработчиками и заложена в структуру сайта. Именно по этому пути и проходит большинство пользователей, чтобы скачать Deductor Academic.
Также из правила 7 следует, что если пользователь зашел на страницу, посвященную деревьям решений, то далее он просмотрит статью "Деревья решений – общие принципы работы".
Рассмотрим выявленные часто встречающиеся наборы. Один набор состоит из трех страниц, указанных в правилах 9 – 11. Мощность остальных не превосходит 2. В таблице 2 представлены 10 часто встречающихся наборов с наибольшими значениями поддержки.
Таблица 2 – Десять популярных наборов с наибольшей поддержкой
| № | Элементы | Поддержка | |
|---|---|---|---|
| Кол-во | % | ||
| 1 | Главная | 3446 | 8,8 |
| 2 | BaseGroup.ru :: Форум :: Бесплатные компоненты | 3040 | 7,76 |
| 3 | BaseGroup.ru :: Нечеткая логика - математические основы | 1385 | 3,54 |
| 4 | BaseGroup.ru :: Деревья решений - общие принципы работы | 1265 | 3,23 |
| 5 | BaseGroup.ru :: Deductor Academic | 1034 | 2,64 |
| 6 | BaseGroup.ru :: IRR - внутренняя норма доходности, ... | 999 | 2,55 |
| 7 | BaseGroup.ru :: Нейронные сети - математический аппарат | 975 | 2,49 |
| 8 | BaseGroup.ru :: Коэффициенты оборачиваемости, Коэффициенты... | 966 | 2,47 |
| 9 | BaseGroup.ru :: Форумы | 877 | 2,24 |
| 10 | BaseGroup.ru :: Регистрация на партнерском портале | 863 | 2,2 |
Самой популярной является главная страница. Она была предусмотрена разработчиками сайта как опорная точка для пользователей: с неё должно начинаться путешествие по сайту, к ней можно всегда быстро вернуться. Так как эта страница имеет высокую поддержку, значит, посетители предусмотренными возможностями пользуются. Так же видно, что востребованы форум и опубликованные статьи.
Самая популярная статья в марте – "Нечеткая логика – математические основы".
Задавая в качестве транзакции ID-сессии, полученные правила и популярные наборы будут более строгие, и их окажется меньше.
В результате было получено одно правило (такое же, как первое правило на рисунке 5) и 31 популярный набор.
Заключение
Исходя из проведенного анализа, можно сделать вывод, что сайт в целом выполняет возложенные на него функции: пользователи просматривают статьи, загружают файл deductor academic, посещают форум. Структура сайта также прослеживается в популярных наборах и правилах. Однако необходимо более детально проанализировать причины того, что главная страница сайта не является наиболее используемой в качестве точки входа на сайт (но это уже выходит за рамки данной статьи).
Таким образом, анализ использования web-ресурсов очень важен в деятельности субъектов сетевой экономики: электронных магазинов, аукционов, бирж. Его результаты позволяют оптимизировать работу портала, найти погрешности в дизайне, узнать предпочтения посетителей, выделить среди них группы. Так появляются возможности привлечения большего количества клиентов, повышения их лояльности, что в результате приводит и к росту прибыли.
- Markov Z, Larose D.T. Data-mining the Web : uncovering patterns in Web content, structure, and usage, - John Wiley & Sons Inc., 2007
- Анализ данных и процессов: учеб. пособие / А. А. Барсегян, М. С. Куприянов, И. И. Холод, М. Д. Тесс, С.И. Елизаров. – 3-е издание перераб. и доп. – СПб.: БХВ-Петербург, 2009
