Web Mining: анализ использования веб-ресурсов, обработка веб-лога
В предыдущей статье ""Web Mining – основные понятия" были рассмотрены элементарные принципы и понятия о функционировании сети Интернет, сложности анализа веб-данных, этапы и категории Web Mining. Данная статья посвящена анализу использования веб-ресурсов. Это направление Web Mining временами также называют анализом потоков кликов (click stream analysis) – упорядоченное множество посещений страниц, которые просмотрел пользователь, попав на веб-сайт.
Необходимые для анализа данные находятся в логах серверов и куки-файлах. При загрузке веб-страницы браузер также запрашивает все вставленные в неё объекты, например графические файлы. В связи с этим возникает проблема с тем, что сервер добавляет в журнал записи о каждом таком запросе. Отсюда вытекает необходимость предобработки данных. После того как выделены отдельные просмотры страниц пользователем, их объединяют в сессию.
Как только данные были очищены и подготовлены для анализа, необходимо задаться следующими вопросами:
- Какая страница является общей точкой входа для пользователей? Заходят ли посетители на сайт через специально предусмотренную разработчиками страницу или же они сразу попадают на другие страницы?
- В каком порядке просматривались страницы? Соответствует ли этот порядок тому, который ожидают от пользователей разработчики?
- Какие другие веб-порталы направляют пользователей на исследуемый сайт? С каких сайтов поступает наибольшее и наименьшее число пользователей?
- Как много страниц обычно просматривает пользователь? Если пользователи уходят с сайта после просмотра небольшого числа страниц, то, возможно, стоит сделать дизайн более дружественным.
- Как долго посетители находятся на сайте? Если это время меньше того, которое ожидают разработчики, то стоит найти причины.
- Как страница является наиболее частой точкой ухода пользователей с сайта? Почему именно с этой страны посетители покидают сайт? Является ли она специально предусмотренной для этого или есть какие-то причины, которые отпугивают пользователя с сайта?
В первой части статьи рассмотрим, как устроены лог-файлы веб-серверов, а также уделим внимание вопросу предобработки полученных данных.
Лог-файлы веб-серверов
Прежде чем приступить непосредственно к анализу потоков кликов, необходимо разобраться с типами доступных данных. Для этого рассмотрим файлы журнала веб-сервера – веб-логи. Для каждого запроса браузера к веб-серверу отклик генерируется автоматически, и все сведения заносятся в веб-лог – текстовый файл с разделителями в кодировке ASCII.
Существуют различные форматы журналов веб-серверов. Главное их отличие заключается в количестве полей. Некоторые из них есть в логе любого формата. Опишем поля, которые являются общими для всех логов.
Поле "удаленный хост". Это поле веб-лога содержит IP-адрес удаленного хоста, создавшего запрос, например "145.243.2.170". Если доступно имя удаленного хоста, то он может быть таким: "whgj3-45.gate.com". Его предпочтительнее использовать, чем IP-адрес, потому как оно может нести в себе ещё и семантический смысл.
Поле "дата/время". В веб-логах может использоваться формат даты-времени в виде "ДД:ЧЧ:ММ:СС", где ДД – это число месяца, ЧЧ:ММ:СС отражает время. Также встречается и более общий формат: "ДД/Мес/ГГГГ:ЧЧ:ММ:СС смещение", где смещение – положительная или отрицательная константа, определяющая часовой пояс относительно GTM (среднего времени по Гринвичу). Например, "09/Jun/1988:03:27:00 -0500" – 3 часа 27 минут 9 июня 1988 года, время сервера на 5 часов позади GTM.
Поле "HTTP запроса". В поле содержится информация о том, что клиентский браузер запросил с веб-сервера, и в нем могут быть выделены четыре части:
- метод запроса (правила, по которым передается данные запроса);
- унифицированный индикатор ресурса (URI);
- заголовок;
- протокол.
Чаще всего встречается метод GET, который используется для запроса содержимого указанного ресурса. Помимо этого могут быть и другие методы: HEAD, PUT, POST.
Унифицированный индикатор ресурса содержит имя страницы/документа и путь к ней/нему. Эта информация может быть использована в анализе частоты посещений для страниц или файлов. Заголовок предоставляет дополнительную информацию о запросе браузера. С помощью него можно определить, например, какие ключевые слова использует пользователь в поисковой машине сайта. Далее указано наименование протокола и его версия.
Поле кода состояния. Не всегда запросы браузеров заканчиваются успешным исходом. Поле кода состояния содержит трехзначное число, обозначающее исход запроса страницы браузером: удачный или неудачный.
Успешной загрузке страницы соответствует код формата "2хх", а "4хх" – ошибке загрузки. Приведем примеры часто встречающихся кодов:
- 2хх (Success) – эти коды информируют о случаях успешного принятия и обработки запроса клиента:
- 200 – успешный запрос ресурса;
- 201 – в результате успешного выполнения запроса был создан новый ресурс;
- 202 – запрос был принят на обработку, но она ещё не завершена;
- 204 – сервер успешно обработал запрос, но в ответе были переданы только заголовки без тела сообщения;
- 3хх (Redirection) – эти коды сообщают, что для успешного выполнения операции необходимо сделать другой запрос:
- 301 – запрошенный документ был окончательно перенесен на новый URI;
- 302 – запрошенный документ временно доступен по другому URI;
- 304 – клиент запросил документ методом GET, использовал заголовок If-Modified-Since или If-None-Match и документ не изменился с указанного момента.
- 305 – запрос к запрашиваемому ресурсу должен осуществляться через прокси-сервер, URI которого указан в поле Location заголовка.
- 4хх (Client Error) – класс кодов, указывающих на наличие ошибок со стороны клиента.
- 400 – запрос не принят сервером из-за наличия синтаксической ошибки;
- 401 – запрос требует идентификации пользователя;
- 403 – сервер понял запрос, но он отказывается его выполнять из-за ограничений в доступе со стороны клиента к указанному ресурсу.
- 404 – сервер понял запрос, но не нашел соответствующего ресурса по указанному URI.
- 5хх (Server Error) – неудачное выполнение операции по вине сервера:
- 500 – любая внутренняя ошибка сервера, которая не входит в рамки остальных ошибок класса 5хх;
- 501 – сервер не поддерживает возможностей, необходимых для обработки запроса;
- 502 – сервер в роли шлюза или прокси получил сообщение о неудачном выполнении промежуточной операции;
- 503 – сервер временно не имеет возможности обрабатывать запросы по техническим причинам (обслуживание, перегрузка и прочее).
Поле переданного количества данных (transfer volume). В нем указан размер отправленного с сервера клиенту файла (web-страницы, графического файла) в байтах. Значения этого поля положительны у запросов методом GET, которые были завершены успешно (код состояния = 200), у остальных они равны нулю.
Эти данные могут быть полезны для контроля сетевого трафика, анализа объема загрузок в течение суток.
Как было ранее сказано, существуют различные форматы веб-логов, которые зависят от конфигурации сервера. Рассмотрим наиболее часто встречающиеся из них.
Common log format (CLF)
Формат CLF поддерживается различными серверными приложениями и включает следующие семь полей:
- удаленный хост;
- идентификация;
- аутентификация;
- дата/время;
- HTTP-запрос;
- код состояния;
- переданное количество данных.
Поле идентификации используется для хранения одинаковой информации, переданной клиентом в случае, если сервер выполняет соответствующую проверку. Оно обычно содержит прочерк, означающий, что информация об идентификации отсутствует.
Если зарегистрированный пользователь посещал сайт, то его имя заносится в поле "аутентификация". В остальных случаях ставится прочерк.
Extended common log format (ECLF)
ECLF – это расширенный вариант формата CLF, полученный добавлением в запись журнала двух полей: направление и пользовательский агент.
Поле "Направление". Это поле содержит URL предыдущего сайта, с которого был перенаправлен клиент. Для файлов, которые загружаются вместе со страницей, этот адрес совпадает с адресом страницы. Здесь содержится важная информация о том, как и откуда пользователи попадают на портал.
Поле "Пользовательский агент". Здесь сосредоточена информация о клиентском браузере и его версии, об операционной системе посетителя. Важно заметить, что данное поле позволяет вычислить ботов. Веб-разработчики могут использовать это для блокировки определенной части электронного портала от подобных программ в целях равномерного распределения нагрузки на сайт. Аналитик по этому полю может отфильтровать данные, оставив только те запаси, которые отражают деятельность реальных посетителей.
Пример записи веб-лога
Рассмотрим пример записи лога формата ECLF.
Пример записи:
149.1xx.120.116 -- smithj [28/OCT/2004:20:27:32-5000] ``GET /Default.htm HTTP/1.1'' 200 1270 ``http:/www.basegroup.ru/'' ''Mozilla/4.0+(compatible;+MSIE+6.0;+Windows+NT+5.0)''
- Удаленный хост: 149.1xx.120.116.
- Идентификация: –.
- Авторизация: smithj.
- Дата/время: [28/OCT/2004:20:27:32-5000].
- Запрос: ``GET /Default.htm HTTP/1.1'' .
- Код состояния: 200.
- Переданное количество данных: 1270.
- Направление: ``http:/www.basegroup.ru/''
- Пользовательский агент: ''Mozilla/4.0+(compatible;+MSIE+6.0;+Windows+NT+5.0)''.
Формат Microsoft IIS
Корпорация Microsoft предложила свой формат веб-лога – MS IIS, который включает записи со следующими полями:
- IP-адрес клиента;
- имя пользователя;
- дата;
- время;
- сервис;
- имя сервера;
- IP-адрес сервера;
- пройденное время;
- количество данных, отправленных клиентом;
- количество данных, отправленных сервером;
- код состояния сервиса;
- код состояния Windows;
- тип запроса;
- цель операции;
- параметры.
Формат IIS содержит наибольшее количество полей, в отличие от других. Такой лог может предоставить максимальное количество информации.
После того как мы извлекли с веб-сервера лог-файл и определились с его форматом, необходимо приступить к предобработке данных.
Предобработка данных
Исходные данные, полученные из лога, нуждаются в предобработке. Какую информацию из него можно извлечь?
- Просмотры страницы.
- Идентификация каждого пользователя.
- Пользовательская сессия, в особенности:
- просмотренные страницы;
- порядок просмотренных страниц;
- продолжительность.
Для чего необходима предобработка веб-данных?
- Очистка данных. Набор данных необходимо отфильтровать от записей, генерируемых автоматически совместно с загрузкой страницы.
- Удаление записей, не отражающих активность пользователя. Веб-боты в автоматическом режиме просматривают множество различных страниц в сети. Их поведение сильно отличается от человеческого, и они не представляют интереса с точки зрения анализа использования веб-ресурсов.
- Определение каждого отдельного пользователя. Большинство порталов в сети Интернет доступны анонимным пользователям. Можно применять информацию о зарегистрированных пользователях, доступные куки-файлы для определения каждого пользователя.
- Идентификация пользовательской сессии. Это означает, что для каждого визита определяются страницы, которые был запрошены и их порядок просмотра. Также пытаются оценить, когда пользователь покинул веб-сайт.
- Нахождение полного пути. Множество людей используют кнопку "Назад" для возвращения к ранее просмотренной странице. Если это происходит, то браузер отображает страницу, ранее сохраненную в кэше. Это приводит к "дырам" в журнале веб-сервера. Знания о топологии сайта могут быть использованы для восстановления таких пропусков.
Рассмотрим пример. Для этого возьмем веб-лог сайта BaseGroup Labs – www.basegroup.ru. Формат – ECLF. Фрагмент используемого лог-файла приведен ниже.
Фрагмент веб-лога
194.187.204.53 - - [08/Mar/2010:18:35:35 +0300] GET /img/btn_close.gif HTTP/1.1 200 377 http://www.basegroup.ru/solutions/scripts/details/pi_analysis/ Mozilla/5.0 (Windows; U; Windows NT 5.1; ru; rv:1.8.1.20) Gecko/20081217 AdCentriaIM/1.7 Firefox/2.0.0.20 sputnik 2.0.1.41
194.187.204.53 - - [08/Mar/2010:18:35:35 +0300] GET /img/formuls/math_921_c5da77d27189b563b0346a015babea75.png HTTP/1.1 200 1138 http://www.basegroup.ru/solutions/scripts/details/pi_analysis/ Mozilla/5.0 (Windows; U; Windows NT 5.1; ru; rv:1.8.1.20) Gecko/20081217 AdCentriaIM/1.7 Firefox/2.0.0.20 sputnik 2.0.1.41
Как было раннее сказано, лог – это текстовый файл. Но так как данные в него заносятся довольно часто и хранится он на сервере продолжительное время, то его размеры могут достигать нескольких гигабайт. Так как пользователи регулярно посещают сайт, то достаточно будет проанализировать данные за один месяц.
В нашем лог-файле возьмем только информацию за март 2010 года. Общее количество записей за указанный период равно 2 725 442. Сразу после импорта данных необходимо привести их к требуемому типу и форматам. Например, значение поля даты-времени в лог-файле записано как [01/Mar/2010:09:47:42 +0300]. С помощью строковых операций и преобразований типов данных можно получить требуемый формат даты. Также из HTTP-запроса необходимо выделить метод, запрашиваемый ресурс и протокол.
Очистка и фильтрация данных
Вначале необходимо удалить записи, генерируемые совместно с загружаемой страницей. Нас не интересует загрузка файлов с расширениями .gif, .jpeg, .js, .css и им подобные. Все это, по сути, части одной страницы. Но не стоит обобщать этот фильтр на файлы с расширениями .html, .exe, так как информация о них может быть полезной. Такой фильтр организовать несложно с помощью элементарных строковых функций. Например, если подстрока ".gif" присутствует в адресе запрошенного ресурса, то её следует пометить. Выявив строки со всеми другими ненужными расширениями, отфильтровываем записи.
Также необходимо провести замену страниц с PHP-запросами. Их можно распознать по знаку вопроса.
После применения фильтра в нашем наборе данных осталось 451 559 записей. Таким образом, был отфильтрован 81%.
Удаление записей, не отражающих активность пользователей
Поисковые машины нуждаются в наиболее актуальной информации, доступной в сети Интернет. Они посылают поисковых агентов и автоматических веб-ботов для выполнения исчерпывающего поиска сайтов. Поведение таких программ на портале сильно отличается от человеческого. Например, бот может запросить все имеющиеся страницы сайта одну за другой. Такие загрузки совершенно не интересны с точки зрения анализа использования веб-ресурсов и могут отрицательно повлиять на точность оценки.
Большинство методов исключения ботов, пауков и поисковых агентов из набора данных основаны на обнаружении их имени в поле пользовательского агента. Часто в их имя может быть включен URL или e-mail адрес.
Практически это можно реализовать поиском в строке заданных подстрок, помечая записи.
В нашем примере 43% записей соответствуют визитам ботов, а 57% – реальным людям (рисунок 1).
Далее помеченные записи отфильтровываются.
Определение пользователей
На этом шаге главной задачей является определение каждого отдельного пользователя, посетившего сайт. Для этого необходимо использовать информацию из поля "Авторизация".
В нашем случае все пользователи сайта были не авторизованы, и в данном поле у всех записей стоит прочерк. Для определения неавторизованных пользователей существует своя методика. Рассмотрим её шаги.
- Создание временного штампа для записей.
- Определить базовую дату. В нашем случае это 01.03.2010.
- Найти, сколько прошло полных дней от базовой даты.
- Умножить полученные значения на 86 400 (количество секунд в сутках).
- Найти прошедшее время в секундах от полуночи.
- Сложить значения, полученные на этапах 1.3 и 1.4. Это и будет временной штамп.
- Упорядочить все записи лога по IP-адресу, затем по временному штампу.
- Каждую отдельную полученную группу IP-адресов определить как отдельного пользователя.
Рассчитанный временной штамп – это прошедшее количество секунд от базовой даты.
Определение сессии
Каждый определенный пользователь в течение исследуемого периода мог посещать портал несколько раз, и вполне возможно, что с различными целями. Поэтому визиты пользователей необходимо разбить на сессии.
Для этого необходимо решить, какой максимальный промежуток времени t может быть между просмотрами отдельных страниц. На рисунке 2 приведен фрагмент данных из примера. Обратим внимание на пользователя 42. 23 марта он посетил 3 страницы, и следующие визиты были им сделаны уже 26 числа. Совершенно очевидно, что у него было две сессии: 23 и 26 марта.
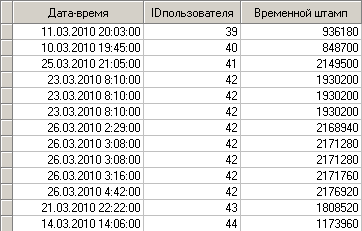
Процедура идентификации каждой отдельной сессии состоит из нескольких шагов.
- Определение времени t – максимальный интервал перехода от одной страницы к другой в течение сессии. Для нашего примера это время равно 3 часам (10800 секунд).
- Сортировка записей, во-первых, по номеру пользователя, во-вторых, по временному штампу.
- Расчет количества секунд, прошедших от предыдущего просмотра.
- Если полученное значение превышает заданный интервал t, то запись рассматривается как начало новой сессии.
Далее в зависимости от поставленных задач анализа можно проводить различные трансформации с данными, например, можно помечать сессии по наличию той или иной страницы.
Дальнейшие шаги предобработки данных
Рассмотренные выше методы предобработки специфичны исключительно для данных веб-логов. Однако это не означает, что сведения уже готовы к использованию и построению моделей. Далее необходимо провести обычные шаги обработки, используемые в KDD, а именно:
- оценка качества данных;
- восстановление пропущенных значений;
- выявление аномальных значений;
- нормализация.
В следующей статье "Web Mining - анализ использования веб-ресурсов, часть 2" рассмотрим дальнейшие шаги анализа веб-данных.
Сценарий того, как можно провести предобработку веб-данных в Deductor, выложен в Банке сценариев.
- Markov Z, Larose D.T. Data-mining the Web : uncovering patterns in Web content, structure, and usage, - John Wiley & Sons Inc., 2007
- Анализ данных и процессов: учеб. пособие / А. А. Барсегян, М. С. Куприянов, И. И. Холод, М. Д. Тесс, С.И. Елизаров. – 3-е издание перераб. и доп. – СПб.: БХВ-Петербург, 2009
