Деревья решений — CART математический аппарат. Часть 1
Общий принцип построения деревьев решений был дан в статье "Деревья решений – основные принципы работы".
В этой статье речь пойдет об алгоритме CART. CART, сокращение от Classification And Regression Tree, переводится как "Дерево Классификации и регрессии" – алгоритм бинарного дерева решений, впервые опубликованный Бриманом и др. в 1984 году [1]. Алгоритм предназначен для решения задач классификации и регрессии. Существует также несколько модифицированных версий – алгоритмы IndCART и DB-CART. Алгоритм IndCART, является частью пакета Ind и отличается от CART использованием иного способа обработки пропущенных значений, не осуществляет регрессионную часть алгоритма CART и имеет иные параметры отсечения. Алгоритм DB-CART базируется на следующей идее: вместо того чтобы использовать обучающий набор данных для определения разбиений, используем его для оценки распределения входных и выходных значений и затем используем эту оценку, чтобы определить разбиения. DB, соответственно означает – "distribution based". Утверждается, что эта идея дает значительное уменьшение ошибки классификации, по сравнению со стандартными методами построения дерева. Основными отличиями алгоритма CART от алгоритмов семейства ID3 являются:
- бинарное представление дерева решений;
- функция оценки качества разбиения;
- механизм отсечения дерева;
- алгоритм обработки пропущенных значений;
- построение деревьев регрессии.
Бинарное представление дерева решений
В алгоритме CART каждый узел дерева решений имеет двух потомков. На каждом шаге построения дерева правило, формируемое в узле, делит заданное множество примеров (обучающую выборку) на две части – часть, в которой выполняется правило (потомок – right) и часть, в которой правило не выполняется (потомок – left). Для выбора оптимального правила используется функция оценки качества разбиения.
Предлагаемое алгоритмическое решение.
Оно вполне очевидно. Каждый узел (структура или класс) должен иметь ссылки на двух потомков Left и Right – аналогичные структуры. Также узел должен содержать идентификатор правила (подробнее о правилах см. ниже), каким либо образом описывать правую часть правила, содержать информацию о количестве или отношении примеров каждого класса обучающей выборки "прошедшей" через узел и иметь признак терминального узла – листа. Таковы минимальные требования к структуре (классу) узла дерева.
Функция оценки качества разбиения
Обучение дерева решений относится к классу обучения с учителем, то есть обучающая и тестовая выборки содержат классифицированный набор примеров. Оценочная функция, используемая алгоритмом CART, базируется на интуитивной идее уменьшения нечистоты (неопределённости) в узле. Рассмотрим задачу с двумя классами и узлом, имеющим по 50 примеров одного класса. Узел имеет максимальную "нечистоту". Если будет найдено разбиение, которое разбивает данные на две подгруппы 40:5 примеров в одной и 10:45 в другой, то интуитивно "нечистота" уменьшится. Она полностью исчезнет, когда будет найдено разбиение, которое создаст подгруппы 50:0 и 0:50. В алгоритме CART идея "нечистоты" формализована в индексе Gini. Если набор данных Т содержит данные n классов, тогда индекс Gini определяется как:
$Gini\,(T) = 1 - \sum\limits_{i=1}^{n}\ p_i^2$ ,
где pi – вероятность (относительная частота) класса i в T.
Если набор Т разбивается на две части Т1 и Т2 с числом примеров в каждом N1 и N2 соответственно, тогда показатель качества разбиения будет равен:
$$Gini_{split}\,(T) = \frac{N_1}{N}\,\cdot\,Gini\,(T_1)\,+\,\frac{N_2}{N}\,\cdot\,Gini\,(T_2)$$
Наилучшим считается то разбиение, для которого Ginisplit(T) минимально.
Обозначим N – число примеров в узле – предке, L, R – число примеров соответственно в левом и правом потомке, li и ri – число экземпляров i-го класса в левом/правом потомке. Тогда качество разбиения оценивается по следующей формуле:
$$Gini_{split}\, = \frac{L}{N}\,\cdot\,\Biggl(1\,-\,\sum_{i=1}^n\,{\biggl(\frac{l_i}{L}\biggr)}^2\Biggr)\,+\,\frac{R}{N}\,\cdot\,\Biggl(1\,-\,\sum_{i=1}^n\,{\biggl(\frac{r_i}{R}\biggr)}^2\Biggr)\,\rightarrow\,\min$$
Чтобы уменьшить объем вычислений формулу можно преобразовать:
$$Gini_{split}\, = \frac{1}{N}\Biggl(L\,\cdot\,\biggl(1\,-\,\frac{1}{L^2}\,\cdot\,\sum_{i=1}^n l_i^2 \biggr)\,+\,R\,\cdot\,\biggl(1\,-\,\frac{1}{R^2}\,\cdot\,\sum_{i=1}^n r_i^2\biggr)\Biggr)\rightarrow\min$$
Так как умножение на константу не играет роли при минимизации:
$$Gini_{split}\, =L\,-\,\frac{1}{L}\,\cdot\,\sum_{i=1}^n l_i^2 \,+\,R\,-\,\frac{1}{R}\,\cdot\,\sum_{i=1}^n r_i^2\rightarrow\min$$
$$Gini_{split}\, =N\,-\,\biggl(\frac{1}{L}\,\cdot\,\sum_{i=1}^n l_i^2 \,+\,\frac{1}{R}\,\cdot\,\sum_{i=1}^n r_i^2\biggr)\rightarrow\min$$
$$\widetilde{G}_{split}\, =\frac{1}{L}\,\cdot\,\sum_{i=1}^n l_i^2 \,+\,\frac{1}{R}\,\cdot\,\sum_{i=1}^n r_i^2\rightarrow\max$$
В итоге, лучшим будет то разбиение, для которого величина максимальна. Реже в алгоритме CART используются другие критерии разбиения Twoing, Symmetric Gini и др., подробнее см. [1].
Правила разбиения
Вектор предикторных переменных, подаваемый на вход дерева может содержать как числовые (порядковые) так и категориальные переменные. В любом случае в каждом узле разбиение идет только по одной переменной. Если переменная числового типа, то в узле формируется правило вида xi <= c. Где с – некоторый порог, который чаще всего выбирается как среднее арифметическое двух соседних упорядоченных значений переменной xi обучающей выборки. Если переменная категориального типа, то в узле формируется правило xi V(xi), где V(xi) – некоторое непустое подмножество множества значений переменной xi в обучающей выборке. Следовательно, для n значений числового атрибута алгоритм сравнивает n-1 разбиений, а для категориального (2n-1 – 1). На каждом шаге построения дерева алгоритм последовательно сравнивает все возможные разбиения для всех атрибутов и выбирает наилучший атрибут и наилучшее разбиение для него.
Предлагаемое алгоритмическое решение.
Договоримся, что источник данных, необходимых для работы алгоритма, представим как плоская таблица. Каждая строка таблицы описывает один пример обучающей/тестовой выборки.
Каждый шаг построения дерева фактически состоит из совокупности трех трудоемких операций.
Первое – сортировка источника данных по столбцу. Необходимо для вычисления порога, когда рассматриваемый в текущий момент времени атрибут имеет числовой тип. На каждом шаге построения дерева число сортировок будет как минимум равно количеству атрибутов числового типа.
Второе – разделение источника данных. После того, как найдено наилучшее разбиение, необходимо разделить источник данных в соответствии с правилом формируемого узла и рекурсивно вызвать процедуру построения для двух половинок источника данных.
Обе этих операции связаны (если действовать напрямую) с перемещением значительных объемов памяти. Здесь намеренно источник данных не называется таблицей, так как можно существенно снизить временные затраты на построение дерева, если использовать индексированный источник данных. Обращение к данным в таком источнике происходит не напрямую, а посредством логических индексов строк данных. Сортировать и разделять такой источник можно с минимальной потерей производительности.
Третья операция, занимающая 60–80% времени выполнения программы – вычисление индексов для всех возможных разбиений. Если у Вас n – числовых атрибутов и m – примеров в выборке, то получается таблица n*(m-1) – индексов, которая занимает большой объем памяти. Этого можно избежать, если использовать один столбец для текущего атрибута и одну строку для лучших (максимальных) индексов для всех атрибутов. Можно и вовсе использовать только несколько числовых значений, получив быстрый, однако плохо читаемый код. Значительно увеличить производительность можно, если использовать, что L = N – R, li = "ni" – ri , а li и ri изменяются всегда и только на единицу при переходе на следующую строку для текущего атрибута. То есть подсчет числа классов, а это основная операция, будет выполняться быстро, если знать число экземпляров каждого класса всего в таблице и при переходе на новую строку таблицы изменять на единицу только число экземпляров одного класса – класса текущего примера.
Все возможные разбиения для категориальных атрибутов удобно представлять по аналогии с двоичным представлением числа. Если атрибут имеет n – уникальных значений. 2n – разбиений. Первое (где все нули) и последнее (все единицы) нас не интересуют, получаем 2n – 2. И так как порядок множеств здесь тоже неважен, получаем (2n – 2)/2 или (2n-1 – 1) первых (с единицы) двоичных представлений. Если {A, B, C, D, E} – все возможные значения некоторого атрибута X, то для текущего разбиения, которое имеет представление, скажем {0, 0, 1, 0, 1} получаем правило X in {C, E} для правой ветви и [ not {0, 0, 1, 0, 1} = {1, 1, 0, 1, 0} = X in {A, B, D} ] для левой ветви.
Часто значения атрибута категориального типа представлены в базе как строковые значения. В таком случае быстрее и удобнее создать кэш всех значений атрибута и работать не со значениями, а с индексами в кэше.
Механизм отсечения дерева
Механизм отсечения дерева, оригинальное название minimal cost-complexity tree pruning, – наиболее серьезное отличие алгоритма CART от других алгоритмов построения дерева. CART рассматривает отсечение как получение компромисса между двумя проблемами: получение дерева оптимального размера и получение точной оценки вероятности ошибочной классификации.
Основная проблема отсечения – большое количество всех возможных отсеченных поддеревьев для одного дерева. Более точно, если бинарное дерево имеет |T| – листов, тогда существует ~[1.5028369|T|] отсечённых поддеревьев. И если дерево имеет хотя бы 1000 листов, тогда число отсечённых поддеревьев становится просто огромным.
Базовая идея метода – не рассматривать все возможные поддеревья, ограничившись только "лучшими представителями" согласно приведённой ниже оценке.
Обозначим |T| – число листов дерева, R(T) – ошибка классификации дерева, равная отношению числа неправильно классифицированных примеров к числу примеров в обучающей выборке. Определим $C_{\alpha}\,(T)$ – полную стоимость (оценку/показатель затраты-сложность) дерева Т как:
$C_{\alpha}\,(T) = R\,(T)\,+\,\alpha\,*\,|T|$, где |T| – число листов (терминальных узлов) дерева, – некоторый параметр, изменяющийся от 0 до + $\infty$. Полная стоимость дерева состоит из двух компонент – ошибки классификации дерева и штрафа за его сложность. Если ошибка классификации дерева неизменна, тогда с увеличением полная стоимость дерева будет увеличиваться. Тогда в зависимости от менее ветвистое дерево, дающее бОльшую ошибку классификации может стоить меньше, чем дающее меньшую ошибку, но более ветвистое.
Определим Tmax – максимальное по размеру дерево, которое предстоит обрезать. Если мы зафиксируем значение $\alpha$, тогда существует наименьшее минимизируемое поддерево $\alpha$, которое выполняет следующие условия:
- $C_{\alpha}\Bigl(T\,(\alpha)\Bigr) = min_{\,\,T \leq T_{\max}}\,C_{\alpha}(T)$
- $if\,\,C_{\alpha}\,(T) = C_{\alpha}\Bigl(T\,(\alpha)\Bigr)\,then\,\,T\,(\alpha)\leq\,T$
Первое условие говорит, что не существует такого поддерева дерева Tmax , которое имело бы меньшую стоимость, чем $T\,(\alpha)$ при этом значении $\alpha$. Второе условие говорит, что если существует более одного поддерева, имеющего данную полную стоимость, тогда мы выбираем наименьшее дерево.
Можно показать, что для любого значения существует такое наименьшее минимизируемое поддерево. Но эта задача не тривиальна. Что она говорит – что не может быть такого, когда два дерева достигают минимума полной стоимости и они несравнимы, т.е. ни одно из них не является поддеревом другого. Мы не будем доказывать этот результат.
Хотя имеет бесконечное число значений, существует конечное число поддеревьев дерева Tmax. Можно построить последовательность уменьшающихся поддеревьев дерева Tmax:
T1 > T2 > T3 >...> {t1},
(где t1 – корневой узел дерева) такую, что Tk – наименьшее минимизируемое поддерево для $[\alpha_k,\,\alpha_{k+1})$. Это важный результат, так как это означает, что мы можем получить следующее дерево в последовательности, применив отсечение к текущему дереву. Это позволяет разработать эффективный алгоритм поиска наименьшего минимизируемого поддерева при различных значениях $\alpha$. Первое дерево в этой последовательности – наименьшее поддерево дерева Tmax имеющее такую же ошибку классификации, как и Tmax, т.е. $T_1 = T(\alpha=0)$. Пояснение: если разбиение идет до тех пор, пока в каждом узле останется только один класс, то T1 = Tmax, но так как часто применяются методы ранней остановки (prepruning), тогда может существовать поддерево дерева Tmax имеющее такую же ошибку классификации.
Предлагаемое алгоритмическое решение.
Алгоритм вычисления T1 из Tmax прост. Найти любую пару листов с общим предком, которые могут быть объединены, т.е. отсечены в родительский узел без увеличения ошибки классификации. R(t) = R(l) + R(r), где r и l – листы узла t. Продолжать пока таких пар больше не останется. Так мы получим дерево, имеющее такую же стоимость как Tmax при = 0, но менее ветвистое, чем Tmax.
Как мы получаем следующее дерево в последовательности и соответствующее значение $\alpha$? Обозначим Tt – ветвь дерева Т с корневым узлом t. При каких значениях дерево T – Tt будет лучше, чем Т? Если мы отсечём в узле t, тогда его вклад в полную стоимость дерева T – Tt станет $C_{\alpha}(\{t\}) = R\,(t)\,+\,\alpha$, где R(t) = r(t)* p(t), r(t) – это ошибка классификации узла t и p(t) – пропорция случаев, которые "прошли" через узел t. Альтернативный вариант: R(t)= m/n, где m – число примеров классифицированных некорректно, а n – общее число классифицируемых примеров для всего дерева.
Вклад Tt в полную стоимость дерева Т составит $C_{\alpha}(T_t) = R\,(T_t)\,+\,\alpha\,|T_t|$, где
$R\,(T_t) = \sum_{{t'}\in {T_t}}{R(t')}$
Дерево T – Tt будет лучше, чем Т, когда $C_{\alpha}\{(t\}) = C_{\alpha}\,(T_t)$, потому что при этой величине они имеют одинаковую стоимость, но T – Tt наименьшее из двух. Когда $C_{\alpha}\{(t\}) = C_{\alpha}\,(T_t)$ мы получаем:
$$R\,(T_t)\,+\,\alpha\,|T_t| = R\,(t)\,+\,\alpha$$
решая для $\alpha$, получаем:
$$\alpha = \frac{R\,(t)\,-\,R\,(T_t)}{|T_t|\,-\,1}$$
Так для любого узла t в Т1 ,если мы увеличиваем $\alpha$, тогда когда
$$\alpha = \frac{R\,(t)\,-\,R\,(T_{1,\,t})}{|T_{1,\,t}|\,-\,1}$$
дерево, полученное отсечением в узле t, будет лучше, чем Т1.
Основная идея состоит в следующем: вычислим это значение для каждого узла в дереве Т1, и затем выберем "слабые связи" (их может быть больше чем одна), т.е. узлы для которых величина
$$g\,(t) = \frac{R\,(t)\,-\,R\,(T_{1,\,t})}{|T_{1,\,t}|\,-\,1}$$
является наименьшей. Мы отсекаем Т1 в этих узлах, чтобы получить Т2 – следующее дерево в последовательности. Затем мы продолжаем этот процесс для полученного дерева и так пока мы не получим корневой узел (дерево в котором только один узел).
Алгоритм вычисления последовательности деревьев.
$T_1 = T\,(\alpha = 0)$
$\alpha_1 = 0$
k = 1
while Tk > {root node} do begin
для всех нетерминальных узлов (!листов) в t Tk
$$g\,(t) = \frac{R\,(t)\,-\,R\,(T_{k,\,t})}{|T_{k,\,t}|\,-\,1}$$
$\alpha_{k+1} = min_{t}\,\,g_k(t)$
Обойти сверху-вниз все узлы и обрезать те, где
$g_k(t) = \alpha_{k+1}$
k = k + 1
end
Узлы необходимо обходить сверху-вниз, чтобы не отсекать узлы, которые отсекутся сами собой, в результате отсечения n-го предка.
Рассмотрим метод подробнее на примере.
В качестве примера вычислим последовательность поддеревьев и соответствующих значений для дерева изображенного на рис. 1.
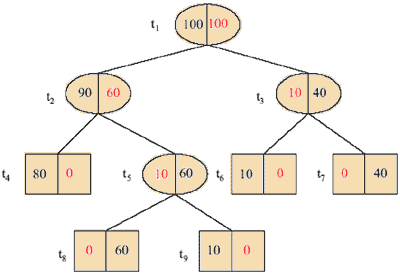
Очевидно, что Т1 = Тmax , так как все листы содержат примеры одного класса и отсечение любого узла (t3 или t5) приведёт к возрастанию ошибки классификации.
Затем мы вычисляем g1(t) для всех узлов t в Т1.
$$g\,(t_1) = \frac{R\,(t_1)\,-\,R\,(T_{1,\,t_1})}{|T_{1,\,t_1}|\,-\,1}$$
R(t1) – ошибка классификации. Если превратить t1 в лист, то следует сопоставить ему какой либо класс; так как число примеров обоих классов одинаково (равно 100), то класс выбираем наугад, в любом случае он неправильно классифицирует 100 примеров. Всего дерево обучалось на 200 примеров (100+100=200 для корневого узла). R(t1) = m/n. m=100, n=200. R(t1) = 1/2.
$R\,(T_1,\,t_1)$– сумма ошибок всех листов поддерева. Считается как сумма по всем листам отношений количества неправильно классифицированных примеров в листе к общему числу примеров для дерева. В примере все делим на 200. Так как для поддерева с корнем в t1 оно же дерево Т1 все листы не имеют неправильно классифицированных примеров, поэтому
$$R\,(T_1,\,t_1) = \sum_1^5\frac{0}{200} = 0$$
$|T_1,\,t_1|$ количество листов поддерева с корнем в узле t1. Итого их – 5.
Получаем:
g1(t1) = (1/2 – 0)/(5 – 1) = 1/8.
g1(t2) = 3/20.
g1(t3) = 1/20.
g1(t5) = 1/20.
Узлы t3 и t5 оба хранят минимальное значение g1, мы получаем новое дерево Т2, обрезая Т1 в обоих этих узлах. Мы получили дерево изображенное на рис.2.
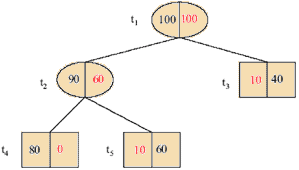
Далее мы продолжаем вычислять g-значение для Т2.
g2(t1) = (100/200 – (0/200 + 10/200 + 10/200)) / (3 – 1) = 2/10.
g2(t2) = (60/200 – (0/200 + 10/200)) / (2 – 1) = 1/4.
Минимум хранится в узле t1, поэтому мы обрезаемы в t1 и получаем корень дерева (T3 = {t1}). На этом процесс отсечения заканчивается.
Последовательность значений получается: $\alpha$1 = 0, $\alpha$2 = 1/20, $\alpha$3 = 2/10. Итак, Т1 является лучшим деревом для [0, 1/20), T2 – для [1/20, 2/10) и Т3 = {t1} для [2/10, $\infty$).
Выбор финального дерева
Итак, мы имеем последовательность деревьев, нам необходимо выбрать лучшее дерево из неё. То, которое мы и будем использовать в дальнейшем. Наиболее очевидным является выбор финального дерева через тестирование на тестовой выборке. Дерево, давшее минимальную ошибку классификации, и будет лучшим. Однако, это не единственно возможный путь.
Продолжение описания см. в статье "Описание алгоритма CART. Часть 2".
- L. Breiman, J.H. Friedman, R.A. Olshen, and C.T. Stone. Classification and Regression Trees. Wadsworth, Belmont, California, 1984.
- J.R. Quinlan. C4.5 Programs for Machine Learning. Morgan Kaufmann, San Mateo, California, 1993.
- Machine Learning, Neural and Statistical Classification. Editors: D. Michie, D.J. Spiegelhalter, C.C. Taylor, 02/17/1994.
