Применение ассоциативных правил для стимулирования продаж
При помощи алгоритма выявления ассоциативных правил можно решать достаточно большой спектр практических задач. В этой статье Вашему вниманию будет представлена типичная задача, решаемая при помощи нахождения ассоциативных зависимостей. Речь идет о механизмах стимулирования продаж, базирующихся на знаниях о наиболее типичном поведении покупателей при оформлении заказов. Применение ассоциативных правил позволяет предугадать, что, вероятнее всего, приобретет клиент, и предложить именно этот товар.
Описание задачи
Имеется некая оптовая фирма, назовем ее "Оптовик". Количество позиций (товаров, которыми она торгует) достигает 10000. Одной из главных задач этой фирмы является работа с покупателями. Это либо более мелкие оптовые фирмы, либо фирмы, которые торгуют в розницу.
Опишем типичный процесс закупки товаров у фирмы "Оптовик".
- Приходит покупатель с определенной суммой, допустим 10 т. р.
- Ему на руки выдается прайс-лист, в котором перечислены имеющиеся товары и их цена.
- Некоторые товары он (покупатель) точно знает, что будет брать (основываясь на предварительных собственных исследованиях, либо на личном опыте и интуиции). Далее менеджер фирмы "Оптовик" вводит те позиции, которые выбрал покупатель, в электронную расходную накладную. Заметим, что если покупатель захотел купить товар A в количестве, допустим, 10 единиц, а на складе осталось 8, то у покупателя остаются деньги, которые он планировал вложить в этот товар. В этом случае он либо вложит оставшиеся деньги в другой товар, либо не потратит их в этот раз и в этой фирме, что явно невыгодно фирме "Оптовик".
- Дальше покупатель задает менеджеру вопрос, например: "На какую сумму получается покупка?" В нашем случае эта сумма равна 8 т. р., а покупатель желал сделать покупку на 10 т.р. Следовательно, он может еще сделать покупку на сумму 2 т.р.
- Следующим этапом процесса типичной закупки, как правило, будет выбор каких-либо товаров, которые ему посоветует менеджер. Заметим: количество позиций огромно, и менеджер просто не в состоянии следить за всем ассортиментом фирмы "Оптовик". И, скорее всего, менеджер посоветует купить товары, являющиеся лидерами продаж, либо те товары, которые находятся рядом (по прайс-листу) с уже купленными. Смысл данного подхода в том, что менеджер не всегда предлагает именно тот товар, который покупатель, скорее всего, хочет (хотя об этом и не знает) приобрести. И, как следствие, товар, который мог бы быть продан, остается на складе.
Описанная выше ситуация – это явная ситуация упущенной выгоды. Задача менеджера фирмы "Оптовик" предугадать желание покупателя и даже подсказать, если покупатель еще до конца не определился в отношении покупки "дополнительных" (не планируемых заранее), либо заменяющих отсутствующие на складе товары, если у клиента нет никаких соображений по этому поводу. Поставленную задачу в полном объеме не в состоянии решить даже очень опытный и талантливый менеджер, так как товаров очень много и некоторые закономерности совсем не очевидны. Помочь менеджеру может такая система, которая будет подсказывать ему список тех товаров, которые склонен купить клиент к уже приобретенным в этот раз (в текущей транзакции).
Вариант решения задачи
Одним из вариантов решения вышеописанной задачи является применение алгоритма выявления ассоциативных правил. Алгоритм выявления ассоциативных правил появился на свет как один из вариантов нахождения типичных шаблонов покупок, совершаемых в супермаркетах. Наша же задача очень сильно корелирует (практически одно и то же) с той, для решения которой был разработан принцип нахождения ассоциативных зависимостей в больших базах данных.
Правила, генерируемые этим алгоритмом, имеют наглядный вид, и в общем случае их можно представить в следующем виде:
Если покупатель купил товар A1 и товар A2 ... и товар An, то он, скорее всего, купит товар B1 и товар B2 ... и товар Bm.
...
Если покупатель купил товар A1 и товар A2 ... и товар An, то он, скорее всего, купит товар C1 и товар C2 ... и товар Ck.
...
Если покупатель купил товар D1 и товар D2 ... и товар Dt, то он, скорее всего, купит товар E1 и товар E2 ... и товар Ep
Здесь (A1, A2, ..., An), ..., (D1, D2, ..., Dt) – те товары, которые покупатель уже купил в текущей транзакции, а (B1, B2, ... Bm), ..., (C1, C2, ..., Ck) , ..., (E1, E2, ..., Ep) – те товары, которые покупатель склонен купить за тот же визит.
Как Вы, наверное, заметили, при одном и тому же условии (товар A1 и товар A2 ... и товар An) может быть несколько вариантов следствий. Из этого можно извлечь следующую выгоду. Если предложенные менеджером товары, входящие в следствие 1-го правила (B1, B2, ... Bm), покупателя все же не устраивают, то у менеджера есть возможность предложить клиенту товары, входящие в следствие другого правила (C1, C2, ..., Ck) с тем же условием (A1, A2, ..., An).
Каждое правило имеет две числовые характеристики:
- Поддержка правила (в контексте данной статьи) – это процентное отношение количества заказов, содержащих все товары, которые входят в правило (в заказ могут входить и другие товары), к общему количеству заказов. Другими словами, поддержка характеризует то, насколько часто покупаются товары, входящие в правило совместно.
- Достоверность правила (в контексте данной статьи) – это процентное отношение количества заказов, содержащих все товары, которые входят в правило, к количеству заказов, содержащих товары, которые входят в условие. Другими словами, достоверность характеризует то, насколько часто покупаются товары, входящие в следствие, если заказ содержит товары, вошедшие во всё правило.
Практический пример
Для демонстрации будут использоваться 2 базы данных. В каждой имеется информация об истории продаж оптовой фирмы за достаточно длительный срок. В первом случае основной деятельностью фирмы является оптовая продажа кондитерских изделий, и анализируемая история продаж составляет 1 год (около 1,5 млн. записей); во втором случае это предприятие, занимающееся оптовой продажей медикаментов, и анализируемая история продаж составляет 1,5 года (около 0,7 млн. записей).
Выявление наиболее интересных правил
Выявление действительно интересных правил – это одна из главных подзадач при вычислении ассоциативных зависимостей. Для того чтобы получить действительно интересные зависимости, нужно разобраться с несколькими эмпирическими правилами, претендующими на звание аксиом:
- Уменьшение минимальной поддержки приводит к тому, что увеличивается количество потенциально интересных правил, однако это требует существенных вычислительных ресурсов. Одним из ограничений уменьшения порога minsupport является то, что слишком маленькая поддержка правила делает его статистически необоснованным.
- Уменьшение порога достоверности также приводит к увеличению количества правил. Значение минимальной достоверности также не должно быть слишком маленьким, так как ценность правила с достоверностью 5% настолько мала, что это правило и правилом считать нельзя.
- Правило со слишком большой поддержкой с точки зрения статистики представляет собой большую ценность, но с практической точки зрения это, скорее всего, означает то, что либо правило всем известно, либо товары, присутствующие в нем, являются лидерами продаж, откуда следует их низкая практическая ценность.
- Правило со слишком большой достоверностью практической ценности в контексте решаемой задачи не имеет, т.к. товары, входящие в следствие, покупатель скорее всего уже купил.
Если значение верхнего предела поддержки имеет слишком большое значение, то в правилах основную часть будут составлять товары – лидеры продаж. При таком раскладе не представляется возможным уменьшить порог minsupport до того значения, при котором могут появляться интересные правила. Причиной тому является просто огромное число правил, и, как следствие, нехватка системных ресурсов. Причем получаемые правила процентов на 95 содержат товары – лидеры продаж. Пример таких правил представлен в табл. 1, 2 (обратите внимание на значения величин, minsupport и maxsupport).
Таблица 1. Пример ассоциативных правил (БД: Кондитерские изделия; minsupport: 1.1; maxsupport: 100; minconfidence: 50; maxconfidence: 95)
| Условие | Следствие | Поддержка (%) |
Достоверность (%) |
|---|---|---|---|
| ПАСТИЛА ВАНИЛЬНАЯ и З-Р ВАНИЛЬНЫЙ и ВФ.УЛИВЕР |
ВФ.АРТЕК-СУПЕР | 1,11 |
52,27 |
| ПЕЧ.ОВСЯНОЕ и З-Р КРЕМ-БРЮЛЕ и ВФ.ШОК-ОРЕХОВЫЕ и З-Р СЛИВОЧНЫЙ |
ВФ.АРТЕК-СУПЕР и З-Р ВАНИЛЬНЫЙ |
1,15 |
59,50 |
| З-Р ФРУКТОВО-ЯГОДНЫЙ | З-Р КРЕМ-БРЮЛЕ | 1,11 |
68,32 |
| ПАСТИЛА ВАНИЛЬНАЯ и З-Р КРЕМ-БРЮЛЕ и ПЕЧ.СДОБНОЕ С ИЗЮМОМ |
ПЕЧ.ОВСЯНОЕ и З-Р ВАНИЛЬНЫЙ |
1,12 |
55,12 |
| ... | ... | ... |
... |
Варьируя верхним и нижним пределами поддержки, можно избавиться от очевидных и неинтересных закономерностей. Как следствие, правила, генерируемые алгоритмом, принимают приближенный к реальности вид (табл. 2).
Таблица 2. Пример ассоциативных правил (БД: Кондитерские изделия; minsupport: 0,9; maxsupport: 10; minconfidence: 40; maxconfidence: 95)
| Условие | Следствие | Поддержка (%) |
Достоверность (%) |
|---|---|---|---|
| ДОЛЬКА МУЛЬТИФРУКТ НЕКТАР | ДОЛЬКА ТОМАТ СОК | 0,93 |
77,33 |
| КФ.ВИЗИТ | КФ.ВЕЧЕРНИЕ | 0,91 |
45,24 |
| З-Р РОМОВЫЙ В ШОК. | З-Р КОФЕЙНЫЙ В ШОК. | 1,39 |
63,97 |
| ... | ... | ... | ... |
В некоторых случаях значение порога minsupport должно быть действительно маленьким. Примером могут быть правила, полученные на основе данных базы данных "Медикаменты". Дело в том, что в некоторых областях торговли товаров настолько много, что каждый из них не владеет рынком даже на несколько процентов. Такой областью является торговля фармацевтической продукцией. К примеру, даже в маленькой аптеке количество наименований товаров составляет около 2-х тысяч. В этом случае появляется еще более острая необходимость в уменьшении минимальной поддержки, которую, в свою очередь, просто не удается уменьшить, не уменьшая верхний порог (см. табл. 3, 4). В таблице 3 представлены примеры правил с большим значением порога maxsupport.
Таблица 3. Пример ассоциативных правил (БД: Медикаменты; minsupport: 0,9; maxsupport: 100; minconfidence: 40; maxconfidence: 95)
| Условие | Следствие | Поддержка (%) |
Достоверность (%) |
|---|---|---|---|
| Андипал # 10 и Эналаприл тб. 0,01 № 20 |
Аскорбиновая к-та 5% 1мл #10 | 1,01 |
64,31 |
| Ортофен 2,5% 3,0 № 10 и Экстракт валерианы 0.02 # 10 |
Аскорбиновая к-та 5% 1мл #10 и Цианокобаламин (вит.В12)500мкг 1мл #10 |
1,02 |
42,63 |
| Диоксидин 1% 5.0 # 10 и Ортофен 2,5% 3,0 № 10 |
Аскорбиновая к-та 5% 1мл #10 и Экстракт валерианы 0.02 # 10 |
1,09 |
48,22 |
| Аскорбиновая к-та 5% 1мл #10 и Цитрамон П тб.# 6 |
Рибоксин 0,2 тб.#50 и Валидол 0,05 капс.#20 |
1,05 |
40,96 |
| ... | ... | ... | ... |
Таблица 4. Пример ассоциативных правил (БД: Медикаменты; minsupport: 0,1; maxsupport: 5; minconfidence: 40; maxconfidence: 95)
А вот что получается, если уменьшить значение максимально доступной поддержки и порога minsupport.
| Условие | Следствие | Поддержка (%) |
Достоверность (%) |
|---|---|---|---|
| Ибупрофен 0,2 тб.#50 и Валидол тб.0.06 # 10 |
Анальгин 0.5 # 10 | 0,10 |
51,89 |
| Валидол тб.0.06 # 10 и Парацетамол 0.5 # 10 и Ацетилсалициловая к-та 0,5 #10 |
Бромгексин 0,008 тб.#10 | 0,11 |
72,84 |
| Аэровит # 30 и Гептавит # 20 |
Декамевит тб.#20 | 0,10 |
52,38 |
| Эуфиллин 0,15 тб.#30 и Бромгексин 0,008 тб.#10 |
Парацетамол 0.5 # 10 | 0,13 |
59,83 |
| ... | ... | ... | ... |
Различные варианты представления правил
Описанные выше механизмы могут быть одной из составных частей информационных систем выписки заказов. Вычисление правил при этом будет проходить в фоновом режиме, т.е. пользователь этой системы (менеджер) этого не видит. Однако при выписке заказов или же по его запросу ему будут представлены вычисленные правила, что поможет менеджеру быть более подготовленным к вопросам клиентов. Вычисленные правила можно использовать как для оперативной подсказки, так и для анализа. Но в обоих случаях ассоциативные правила нужно грамотно представить пользователю. Для этого можно использовать различные отображения, главная задача которых – быть максимально понятными и легко усваиваемыми.
Вашему вниманию будут представлены четыре варианта отображения ассоциативных правил: в виде обычной таблицы (см. табл. 1-4), в виде форматированного текста (текст правил 1), в виде дерева (рис. 1), в виде перекрестной таблицы (рис. 2). У каждого отображения есть как свои преимущества, так и недостатки, и выбор конкретного зависит как от тех целей, которые Вы хотели бы достигнуть, так и от особенностей личного восприятия.
Ассоциативные правила в виде обычной таблицы
Одним из самых простых для восприятия визуализаций ассоциативных правил является таблица (см. табл. 1-4). Ниже описаны преимущества и недостатки использования обычной таблицы при анализе выявленных зависимостей.
Достоинства:
- Легко понять, где условие, а где следствие (в разных столбцах).
- Возможность экспорта в большинство форматов.
- Возможность сортировки по условию, по следствию, по поддержке, по достоверности.
- Возможность фильтрации по условию, по следствию, по поддержке, по достоверности.
Недостатки:
- Очень большое количество правил приводит к генерации громоздкого документа и, как следствие, к сложность для понимания.
Ассоциативные правила в виде форматированного текста
Самой естественной конструкцией для восприятия правил является конструкция вида: ЕСЛИ "Условие" ТО "Следствие". Такой вариант отображения правил – наиболее доступная форма представления.
Правило N 6
ЕСЛИ Метронидазол 0,25 тб.#10
ТО Ибупрофен 0,2 тб.#50
Поддержка = 1,20%
Достоверность = 44,62%
Правило N 7
ЕСЛИ Пиридоксина г/х (вит.В6) 2мг тб.#50
ТО Магния сульфат 25% 5мл #10
Поддержка = 0,60%
Достоверность = 42,30%
...
Достоинства:
- Естественная запись правила;
- Возможность экспорта в .rtf файл;
- Возможность сортировки по условию, по следствию, по поддержке, по достоверности;
- Возможность фильтрации по условию, по следствию, по поддержке, по достоверности.
Недостатки:
- Очень большое количество правил приводит к генерации громоздкого документа, и как следствие сложность в понимании.
Ассоциативные правила в виде дерева правил
Один из вариантов отображения ассоциативных правил – это дерево правил. На первый взгляд использование следующего представления неоправданно с точки зрения понимания смысла правил, но при частом использовании этот визуализатор становится просто незаменимым.
Правило читается следующим образом:
- Выражение, которое будет условием правила собирается начиная с текущего (выделенного) узла.
- Далее, двигаясь к корневому узлу, к выражению добавляется "И" плюс "значение родительского узла".
- Процедура (2) повторяется рекурсивно до тех пор, пока не достигнет родительского узла.
- Следствия найденного условия (если такие имеются) находятся справа от дерева в таблице.
Например, правила для выделенного узла (см. рис. 1) будут выглядеть так:
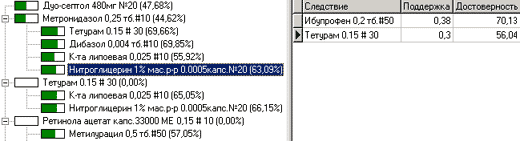
Достоинства:
- Компактный вид.
- Группировка правил по условию.
- Возможность отображения значений поддержки и достоверности правила в графическом виде.
Недостатки:
- Необычное представление правил, и, как следствие, сложность понимания правил на первых порах.
Ассоциативные правила в виде перекрестной таблицы
Еще одним вариантом визуализации ассоциативных правил является перекрестная таблица. В этой таблице по оси X перечислены все правила, а по оси У – все товары, вошедшие в правила.
Правило читается следующим образом:
- Выбирается какой-либо столбец. Это будет одно правило.
- В условие входят товары, обозначенные знаком "+".
- В следствие входят товары, обозначенные знаком "=".
- Поддержка и достоверность правила указаны во 2-й и 3-й строках соответственно.
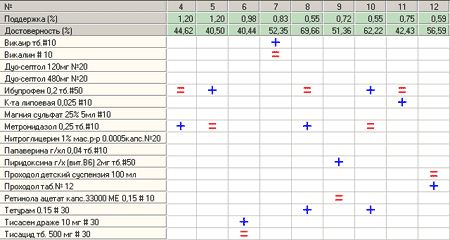
Достоинства:
- Возможность увидеть все товары, присутствующие во всех правилах.
- Возможность сортировки по условию, по следствию, по поддержке, по достоверности.
- Возможность фильтрации по условию, по следствию, по поддержке, по достоверности.
Недостатки:
- Очень большое количество товаров, присутствующих в правилах, вызывает некоторое неудобство при анализе закономерностей.
Заключение
В данной статье было описано и продемонстрировано на практических примерах решение задачи нахождения стандартных шаблонов покупок при помощи алгоритма выявления ассоциативных правил. Однако применимость алгоритма этим не ограничивается. При помощи данного алгоритма можно находить закономерности между связанными событиями, т. е. если исходные данные представлены в виде событий, то на этих данных можно построить ассоциативные закономерности. Одним из таких примеров может служить нахождение зависимостей вида: ЕСЛИ "РЕЗУЛЬТАТЫ АНАЛИЗОВ" ТО "ЗАБОЛЕВАНИЯ", где "РЕЗУЛЬТАТЫ АНАЛИЗОВ" – это результаты анализов пациента, а "ЗАБОЛЕВАНИЯ" – это список заболеваний, которыми, возможно, болеет данный пациент. Список же потенциально возможных областей очень большой.
P.S. Все правила, приведенные выше, были одобрены специалистами по продажам кондитерской и фармацевтической продукций.
