Очистка и разбор текста
Введение
Возможности машинной обработки информации внутри организации варьируются в зависимости от степени структуризации данных. Чем выше степень структурированности данных, тем больше возможностей для их автоматизированной обработки. Данные можно поделить на 3 части:
- Высоко структурированные. Это такого рода данные, как счета, платежные документы, отчеты и прочее. Для такого рода данных есть четкие форматы, правила, жестко задан внешний вид. Обычно они хранятся в базах данных компании.
- Частично структурированные. Описания деталей и продукции, технологическая документация, сведения о сотрудниках и прочее. Для этих данных определены некоторые правила и форматы, но в самом общем виде.
- Неструктурированные. Это электронные письма, сведения о конкурентах, докладные записки и прочее сведения, которые пишутся в свободной форме.
Очевидно, что механизмы подготовки, фильтрации, анализа и обработки, например, сведений, представленных в виде отчетов, значительно мощнее, чем механизмы обработки произвольного текста. В связи с этим, если мы хотим использовать автоматизированные механизмы обработки, необходимо применять способы повышения уровня структурированности используемых данных.
Значительная часть информации в организации представлена в частично структурированном виде – вот для таких текстов возможно создание механизмов, преобразующих их к четкому (структурированному) виду. Например, у нас есть описание препарата "Инсулин ЛЕНТЕ SPP сусп.40 ЕД/1 мл 10 мл". Необходимо данные очистить от незначимых и искаженных сведений и выделить название препарата, фасовку, дозировку и т.п. Назовем этот процесс стандартизацией. Стандартизованную информацию значительно проще обрабатывать, искать, формировать на их основе буклеты и прайс-листы, делать переводы на другие языки.
В статье описан вариант решения задачи очистки и разбора частично структурированных текстов.
Описание проблемы
Возьмем для примера описание клавиатуры: "Клавиатура Defender, Windows-совместимая, разъем PS/2, 124 клавиши". Такого рода описания встречаются практически в любой сфере деятельности.
Необходимо данный текст преобразовать к виду:
| Поле | Значение |
|---|---|
| Тип устройства | Клавиатура |
| Торговая марка | Defender |
| Интерфейс | PS/2 |
| Совместимость | Windows |
Несмотря на то, что в различных предметных областях используются различные термины и понятия, есть то, что объединяет все такие тексты. Во-первых, это неестественный язык, поэтому они пишутся не как предложения, а по совершенно другим правилам; гораздо проще. Во-вторых, описания практически всегда схожи друг с другом по структуре. В-третьих, чаще всего используются один и тот же относительно небольшой, если сравнивать с естественной речью, набор слов. В-четвертых, очень часто встречаются аббревиатуры и сокращения. Используя эту информацию, можно предложить решение, позволяющее автоматизировать работу по очистке и разбору текста.
Вариант решения задачи
Нашей компанией разработана система, позволяющая решать данную задачу. Для этого используется специализированная база знаний, в которую импортируются стандартизируемые материалы. В базе знаний накапливаются сведения о предметных областях, правилах очистки и разбора текстов. Работает это следующим образом.
Перед началом разбора пользователь формирует шаблон разбора для конкретной предметной области, на основе которого в дальнейшем и производится анализ текстов. Например:
| Предметная область | Периферийные устройства ПК |
|---|---|
| Шаблон разбора | Тип устройства |
| Торговая марка | |
| Изготовитель | |
| ГОСТ | |
| Интерфейс | |
| Совместимость | |
| Сертификаты | |
| Цвет |
После подготовки такого шаблона и начинается, собственно, работа по разбору текста.
Первые тексты пользователь разбирает самостоятельно, т.е. указывает, что "клавиатура" – это тип устройства, "серый" – это цвет. При этом он фактически обучает программу, как нужно разбирать данные. По мере того, как программе показывают все больше примеров, она накапливает все больше знаний и начинает угадывать все больше вариантов разбора.
Сильной стороной программы является то, что она использует самообучающиеся алгоритмы, позволяющие на лету обучаться правилам разбора, с учетом особенностей конкретной предметной области. Благодаря такому подходу система, вначале не имея никаких жестко заложенных алгоритмов разбора, по мере работы обучается и начинает помогать пользователю, предлагая правильные варианты разбора. В системе используются оригинальные эффективные алгоритмы, позволяющие корректно анализировать текст с ошибками, пропущенными и/или лишними словами и различными вариантами расположения слов.
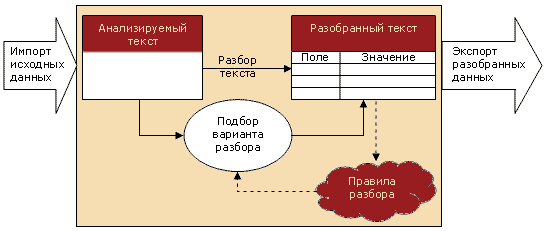
Еще одно интересной особенностью системы является то, что если пользователь начинает работать с предметной областью отличной от обрабатываемой до этого, но достаточно близкой к ней, программа в состоянии использовать ранее найденные правила разбора, т.е. если вы перейдете после описания клавиатур к разбору сведений о мониторах, система будет в состоянии использовать "опыт", накопленный при анализе клавиатур.
Результаты
Система на практике демонстрирует хорошие результаты разбора, причем вне зависимости от языка. После начала работы по разбору текста по какой-либо предметной области, обработав буквально нескольких десятков текстов, программа начинает "угадывать", как правильно нужно разбирать и по мере накопления знаний увеличивает точность разбора, достаточно быстро доходя до уровня 80-90% верно обработаных текстов.
В результате использование данной системы позволяет, во-первых, значительно (в разы) увеличить скорость обработки текстов, во-вторых, повысить качество благодаря тому, что одни и те же термины всегда разбираются идентично. При ручной обработке периодически возникают разночтения. В-третьих, после "обучения системы" использовать менее квалифицированные карды для обработки значительной части текстов, т. е. повысить эффективной работы.
В организациях накопились огромные объемы данных, которыми неудобно пользоваться из-за их "нетехнологичности". Конечно, специалист скорее всего разберется с любым грамотно составленным описанием. Но в случае машинной обработки необходимо представить сведения в удобном именно для машинной обработки виде, т.е. в стандартизованном. Описанная система позволяет значительно повысить возможности автоматизированной обработки частично структурированных данных.
Еще одной перспективной областью применения использованных в программе механизмов является поддержка процесса перевода. Дело в том, что система сохраняет данные не только о правилах разбора, но и в том, как до этого разбирался текст. Программа автоматически создает и пополняет словари, поэтому имея переводы слов, возможен автоматический перевод уже стандартизованного текста и генерация на их основе многоязычных прайс-листов, буклетов, описаний и т.п.
