Кластеризация
Кластеризация, которую иногда называют «сегментацией», подразумевает выделение из исходного множества данных групп объектов со схожими свойствами и часто выступает первым шагом при анализе данных. Разбиение на группы позволяет упростить работу с данными, после кластеризации применяются другие методы, для каждой группы строится отдельная модель.
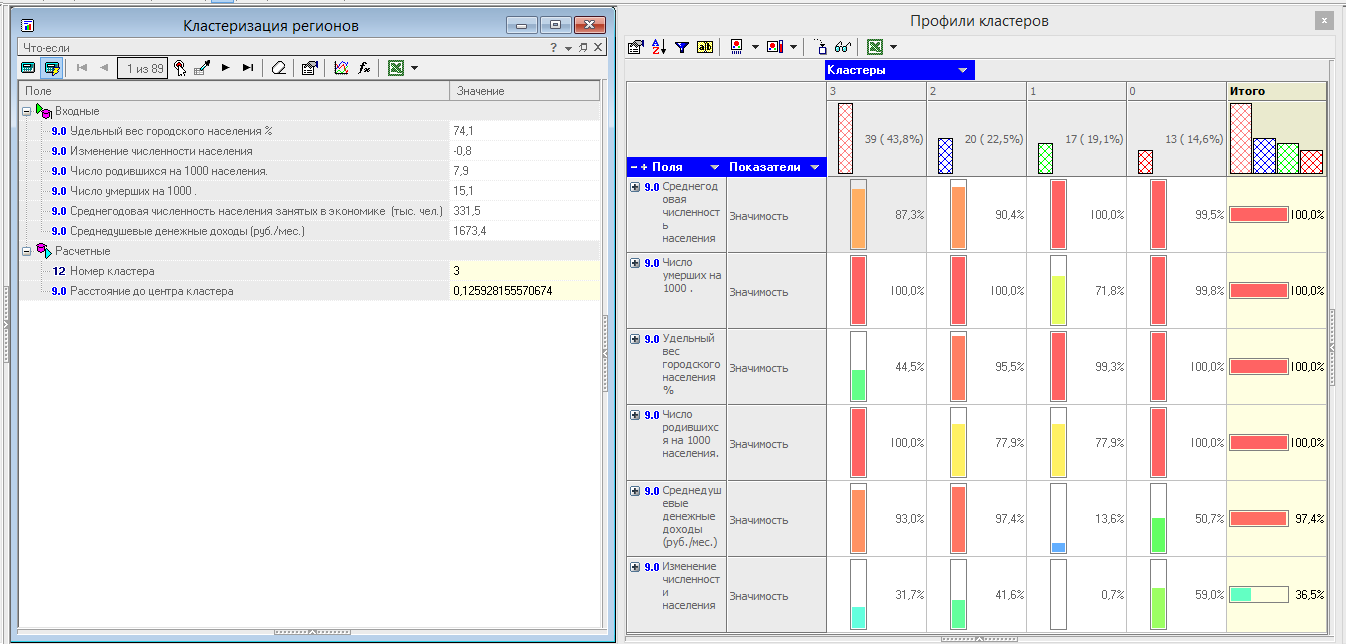
Примеры применения
Сегментация и построение профилей клиентов. С помощью кластеризации можно выделить сегменты с группами "похожих" объектов. Данный алгоритм дает возможность выделить характерные признаки и персональные предпочтения клиентов, оценить наиболее и наименее доходные или активные сегменты. Это позволяет решить задачи разработки маркетинговых акций, направленных на определенные сегменты клиентов, повышает эффективность работы с ними.
Выявление целевой аудитории – наиболее ценной, перспективной, влиятельной группы потребителей, на которую, в первую очередь, будет направлена маркетинговая стратегия. Позволяет решить задачи разработки рекламного сообщения и подбора медиаканалов для его размещения, позиционирования, выбора товарного ассортимента и каналов дистрибуции… Концентрация усилий на целевой аудитории обеспечит максимизацию прибыли в сегменте.
Каннибализация товаров: продукты, находящиеся в одной рыночной нише, "поедают" друг друга, то есть конкурируют за потребителя между собой. Алгоритм дает возможность выделять товары, находящиеся в «зоне риска», прогнозировать эффект каннибализации и управлять им.
Анализ миграции клиентов – перемещение клиентов между поставщиками товаров и услуг, причиной которой является изменение их запросов со временем. Рассматриваемые алгоритмы позволяют прогнозировать миграцию клиентов, визуализировать ее, оценить изменение их ценности для компании, определить причину миграции. В результате происходит укрепление отношений с ценными клиентами и противодействие оттоку.
Описание алгоритма
В Deductor Studio подобный класс задач реализуется посредством алгоритма k-means и его разновидности g-means.
К наиболее простым и эффективным алгоритмам кластеризации относится k-means. Он состоит из четырех шагов.
- Задается число кластеров k, которое должно быть сформировано из объектов исходной выборки.
- Случайным образом выбирается k записей, которые будут служить начальными центрами кластеров. Начальные точки, из которых потом вырастает кластер, часто называют «семенами». Каждая такая запись представляет собой своего рода «эмбрион» кластера, состоящий только из одного элемента.
- Для каждой записи исходной выборки определяется ближайший к ней центр кластера.
- Производится вычисление центроидов - центров тяжести кластеров. Это делается путем определения среднего для значения каждого признака всех записей в кластере. Затем старые центры кластеров смещаются в его центроид. Таким образом, центроиды становятся новыми центрами кластеров для следующей итерации алгоритма.
Остановка алгоритма производится, когда границы кластеров и расположение центроидов перестает изменяться, то есть на каждой итерации в каждом кластере остается один и тот же набор записей. Алгоритм k-means обычно находит набор стабильных кластеров за несколько десятков итераций.
Одним из недостатков k-means является отсутствие ясного критерия для выбора оптимального числа кластеров. Чтобы решить данную проблему, было разработано большое количество алгоритмов, в том числе алгоритм g-means, позволяющий производить автоматический выбор оптимального числа кластеров на основании гауссовского (нормального) закона распределения, откуда и название алгоритма.
Подробную информацию о методах кластеризации можно получить в статье «Алгоритмы кластеризации на службе Data Mining».