
Введение
Нередко возникают ситуации, когда в обучающем наборе данных доля примеров некоторого класса слишком мала (этот класс будем называть миноритарным, а другой, сильно представленный, — мажоритарным). Такие тенденции хорошо заметны в кредитном скоринге, в медицине, в директ-маркетинге. Построенный на таких наборах данных классификатор может оказаться абсолютно неэффективным.
Следует отметить то, что могут отличаться и издержки ошибочной классификации. Причем неверная классификация примеров миноритарного класса, как правило, обходится в разы дороже, чем ошибочная классификация примера мажоритарного класса.
Одним из подходов для решения указанной проблемы является применение различных стратегий сэмплинга, которые можно разделить на две группы: случайные и специальные.
Восстановление баланса классов может проходить двумя путями. В первом случае удаляют некоторое количество примеров мажоритарного класса (undersampling), во втором – увеличивают количество примеров миноритарного (oversampling). Простейшие подходы сэмплинга описаны в книге «Бизнес-аналитика: от данных к знаниям» [1] (обучение в условиях несбалансированности классов) и в учебном курсе (K.01 Корпоративные аналитические системы), а данная статья посвящена более сложным методам.
Перейдем к кратким теоретическим сведениям о наиболее распространенных стратегиях сэмплинга, а затем некоторые из них сравним, применив на наборе данных с несбалансированными классами.
Удаление примеров мажоритарного класса
Рассмотрим классические стратегии удаления примеров мажоритарного класса из набора данных.
Случайное удаление примеров мажоритарного класса (Random Undersampling)
Это самая простая стратегия. Для этого рассчитывается число $K$ – количество мажоритарных примеров, которое необходимо удалить для достижения требуемого уровня соотношения различных классов (один из способов того, как это сделать, будет описан в экспериментальной части). Затем случайным образом выбираются $K$ мажоритарных примеров и удаляются.
На рисунке 1 изображены примеры некоторого набора данных в двумерном пространстве признаков до и после использования указанной стратегии сэмплинга.
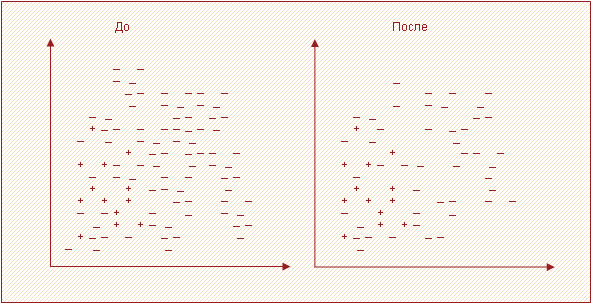
Примеры из мажоритарного класса могут удаляться не только случайным образом, но и по определенным правилам. Перейдем к рассмотрению таких стратегий.
Поиск связей Томека (Tomek Links)
Пусть примеры $E_i$ и $E_j$ принадлежат к различным классам, $d(E_i, E_j)$ – расстояние между указанными примерами. Пара $(E_i, E_j)$ называется связью Томека, если не найдется ни одного примера $E_l$ такого, что будет справедлива совокупность неравенств (1):
$\begin{cases} {d(E_i, E_l)< d(E_i, E_j)}\\ {d(E_j, E_l)< d(E_i, E_j)} \end{cases} $, (1)
Согласно данному подходу, все мажоритарные записи, входящие в связи Томека, должны быть удалены из набора данных. Этот способ хорошо удаляет записи, которые можно рассматривать в качестве «зашумляющих». На рисунке 2 визуально показан набор данных в двумерном пространстве признаков до и после применения стратегии поиска связей Томека.
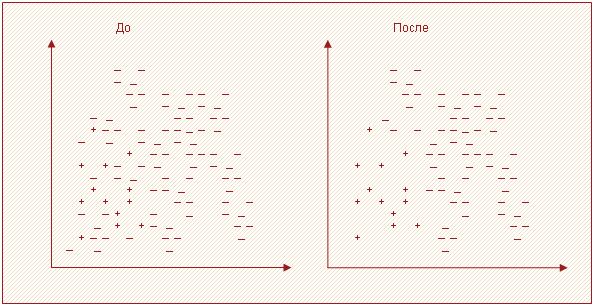
Правило сосредоточенного ближайшего соседа (Condensed Nearest Neighbor Rule)
Пусть L – исходный набор данных. Из него выбираются все миноритарные примеры и (случайным образом) один мажоритарный. Обозначим это множество как S. Все примеры из L классифицируются по правилу одного ближайшего соседа (1-NN). Записи, получившие ошибочную метку, добавляются во множество S (рисунок 3).
Таким образом, мы будем учить классификатор находить отличие между похожими примерами, но принадлежащими к разным классам.
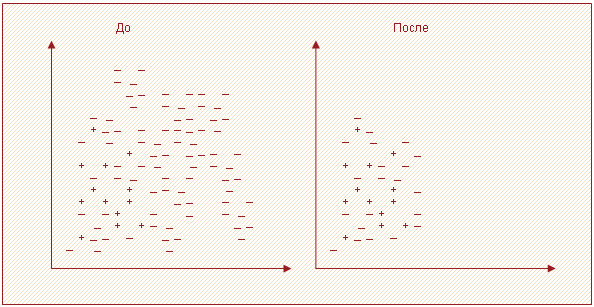
Односторонний сэмплинг (One-side sampling, one-sided selection)
Главная идея этой стратегии – это последовательное сочетание предыдущих двух, рассмотренных выше.
Для этого на первом шаге применяется правило сосредоточенного ближайшего соседа, а на втором – удаляются все мажоритарные примеры, участвующие в связях Томека.
Таким образом, удаляются большие «сгустки» мажоритарных примеров, а затем область пространства со скоплением миноритарных очищается от потенциальных шумовых эффектов.
Правило «очищающего» соседа (neighborhood cleaning rule)
Эта стратегия также направлена на то, чтобы удалить те примеры, которые негативно влияют на исход классификации миноритарных.
Для этого все примеры классифицируются по правилу трех ближайших соседей. Удаляются следующие мажоритарные примеры:
- получившие верную метку класса;
- являющиеся соседями миноритарных примеров, которые были неверно классифицированы.
Теперь рассмотрим другой подход – увеличение числа примеров миноритарного класса.
Увеличение числа примеров миноритарного класса
Дублирование примеров миноритарного класса (Oversampling)
Самый простой метод – это дублирование примеров миноритарного класса. В зависимости от того, какое соотношение классов необходимо, выбирается количество случайных записей для дублирования.
Такой подход к восстановлению баланса не всегда может оказаться самым эффективным, поэтому был предложен специальный метод увеличения числа примеров миноритарного класса – алгоритм SMOTE (Synthetic Minority Oversampling Technique).
Алгоритм SMOTE
Эта стратегия основана на идее генерации некоторого количества искусственных примеров, которые были бы «похожи» на имеющиеся в миноритарном классе, но при этом не дублировали их. Для создания новой записи находят разность $d = X_b – X_a$, где $X_a, X_b$ – векторы признаков «соседних» примеров $a$ и $b$ из миноритарного класса. Их находят, используя алгоритм ближайшего соседа (KNN). В данном случае необходимо и достаточно для примера $b$ получить набор из $k$ соседей, из которого в дальнейшем будет выбрана запись $b$. Остальные шаги алгоритма KNN не требуются.
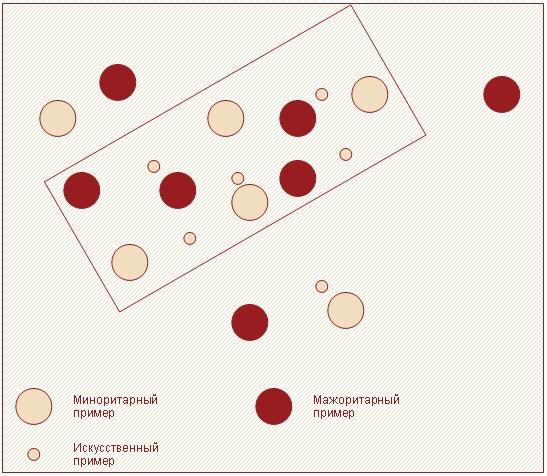
Далее из $d$ путем умножения каждого его элемента на случайное число в интервале (0, 1) получают $\widehat{d}$. Вектор признаков нового примера вычисляется путем сложения $X_a$ и $\widehat{d}$. Алгоритм SMOTE позволяет задавать количество записей, которое необходимо искусственно сгенерировать. Степень сходства примеров $a$ и $b$ можно регулировать путем изменения значения $k$ (числа ближайших соседей). На рисунке 4 схематично изображено то, как в двумерном пространстве признаков могут располагаться искусственно сгенерированные примеры.
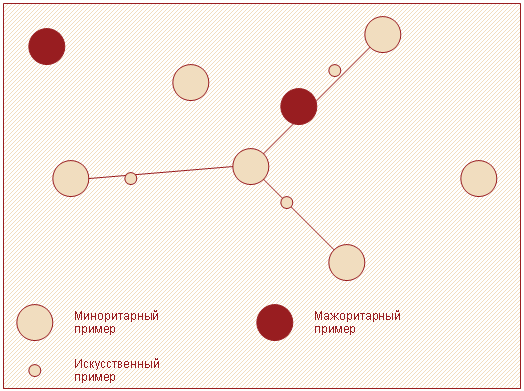
Данный подход имеет недостаток в том, что «вслепую» увеличивает плотность примерами в области слабо представленного класса (рисунок 5). В случае, если миноритарные примеры равномерно распределены среди мажоритарных и имеют низкую плотность, алгоритм SMOTE только сильнее перемешает классы.
В качестве решения данной проблемы был предложен алгоритм адаптивного искусственного увеличения числа примеров миноритарного класса ASMO (Adaptive Synthetic Minority Oversampling).
Алгоритм ASMO
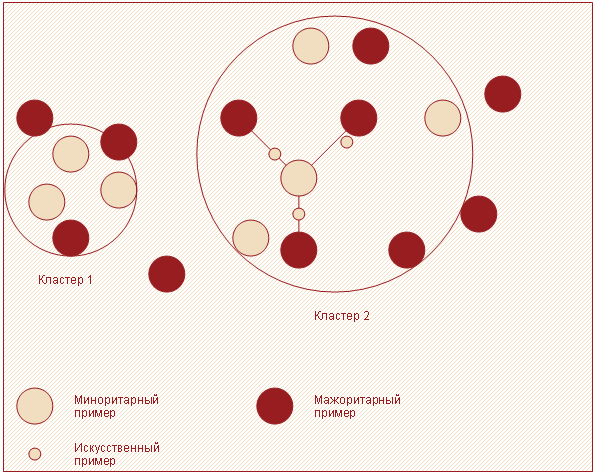
- Если для каждого $i$-ого примера миноритарного класса из $k$ ближайших соседей $g$ $(g \leq k)$ принадлежит к мажоритарному, то набор данных считается «рассеянным». В этом случае используют алгоритм ASMO, иначе применяют SMOTE (как правило, $g$ задают равным 20).
- Используя только примеры миноритарного класса, выделить несколько кластеров (например, алгоритмом k-means).
- Сгенерировать искусственные записи в пределах отдельных кластеров на основе всех классов. Для каждого примера миноритарного класса находят m ближайших соседей, и на основе них (также как в SMOTE) создаются новые записи.
Такая модификация алгоритма SMOTE делает его более адаптивным к различным наборам данных с несбалансированными классами. Общее представление идеи данной стратегии показано на рисунке 6.
Пример (задача о моллюсках)
Сравним практически некоторые из описанных стратегий на наборе данных про моллюсков (набор данных взят с UCI machine learning repository [2]). В нем представлены физиологические сведения об этих животных. Имеются следующие поля:
- пол;
- длина;
- диаметр (линия, перпендикулярная длине);
- высота;
- масса всего моллюска;
- масса без раковины;
- масса всех внутренних органов (после обескровливания);
- масса раковины (после высушивания);
- зависимая переменная: количество колец (в год на раковине моллюска появляется 1,5 кольца).
Изначально набор данных предназначен для решения задачи регрессии. По количеству колец на раковине определяется возраст моллюска. Для классификации в условиях несбалансированности создадим новую выходную переменную, принимающую только два значения. Для этого, предположим, что если количество колец у моллюска не превосходит 18, то для нас он будет считаться молодым, в противном случае – старым.
Также проимитируем ситуацию различия издержек и рассмотрим случаи, когда неверное отнесение старого моллюска к молодым может принести бо́льшие издержки, чем в случае неверной классификации фактически молодого.
Таким образом, мы получили набор данных с сильно несбалансированными классами, где значение «молодой» было присвоено 4083 записям (97,7%), а значение «старый» – 94 записям (2,3%). Далее стратифицированным сэмплингом были получены тестовый и обучающий наборы данных.
Прежде чем восстанавливать баланс между классами, вернемся к понятию издержек классификации. Во многих приложениях, таких как кредитный скоринг, директ-маркетинг, издержки при ложноположительной ($С_{10}$) классификации в несколько раз выше, чем при ложноотрицательной (обозначим их как $С_{01}$). При пороге отсечения 0,5 количество миноритарных примеров необходимо увеличить в $С_{10}/С_{01}$ раз (при условии что $С_{00} = С_{11} = 0$). Либо во столько же уменьшить мажоритарный класс (теоретическое обоснование этого утверждения изложено в работе [1]).
Сравним следующие подходы к восстановлению баланса между классами: случайное удаление примеров мажоритарного класса, дублирование примеров миноритарного класса, специальные методы увеличения числа примеров (алгоритмы SMOTE и ASMO).
Для алгоритмов SMOTE и ASMO количество ближайших соседей для генерации примеров установим равным 5.
Алгоритм ASMO признал набор данных нерассеянным (среди 100 ближайших соседей не нашлось даже 20 примеров из мажоритарного класса). Однако проигнорируем это сообщение и посмотрим, какой будет результат, если генерировать примеры, используя записи из каждого класса. Для кластеризации применен алгоритм k-means (k = 5).
После восстановления баланса строилась логистическая регрессия с порогом отсечения 0,5, и подсчитывались издержки. Результаты представлены на рисунке 7.
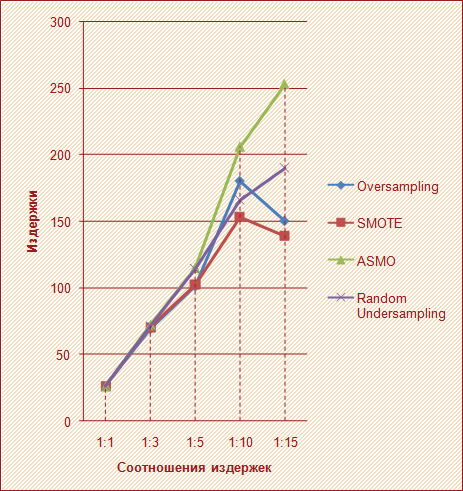
Из рисунка 6 видно, что наилучшим образом показал себя алгоритм SMOTE, так как издержки в данном случае оказались самыми меньшими. ASMO проявил себя хуже, однако стоит напомнить, что набор данных не рассеян и согласно данной стратегии необходимо было использовать SMOTE.
Итак, мы рассмотрели различные подходы сэмплинга для решения проблемы несбалансированности классов. Помимо него существуют стратегии, согласно которым происходит модификация алгоритма обучения, но их рассмотрение выходит за рамки данной статьи.
В таблице 1 приведено описание файлов с наборами данных, которые использовались в примере. Их можно найти в архиве [3].
Таблица 1 – Наборы данных
| Описание набора данных | Файл |
|---|---|
| Исходный набор данных: Abalone Data Set (классы не выделены) | abalone_data.txt |
| Исходный обучающий набор данных | dataset75.txt |
| Тестовый набор данных | testdataset.txt |
| Набор данных с искусственными примерами. Алгоритм SMOTE. Соотношение издержек 1:3 | syntsmote1_3.txt |
| Набор данных с искусственными примерами. Алгоритм SMOTE. Соотношение издержек 1:5 | syntsmote1_5.txt |
| Набор данных с искусственными примерами. Алгоритм SMOTE. Соотношение издержек 1:10 | syntsmote1_10.txt |
| Набор данных с искусственными примерами. Алгоритм SMOTE. Соотношение издержек 1:15 | syntsmote1_15.txt |
| Набор данных с искусственными примерами. Алгоритм ASMO. Соотношение издержек 1:3 | syntasmot1_3.txt |
| Набор данных с искусственными примерами. Алгоритм ASMO. Соотношение издержек 1:5 | syntasmot1_5.txt |
| Набор данных с искусственными примерами. Алгоритм ASMO. Соотношение издержек 1:10 | syntasmot1_10.txt |
| Набор данных с искусственными примерами. Алгоритм ASMO. Соотношение издержек 1:15 | syntasmot1_15.txt |
- Elchan Ch. The Foundations of Cost-Sensitive Learning // In Proc. of the 17th International Joint Conference on Artificial Intelligence, 2001. — P. 973–978).
- Garcia S., Herrera F. Evolutionary Undersampling for Classification with Imbalanced Datasets: Proposals and Taxonomy// Evolutionary Computation 17(3), 2009. – P. 275-306.
- Chawla N., Bowyer, K., Hall, L., Kegelmeyer, W. SMOTE: Synthetic Minority Over-sampling Technique // Journal of Artificial Intelligence Research, 2002, 16. – P. 341-378.
- He H., Garcia A. Learning from Imbalanced Data // IEEE transactions on knowledge and data engineering, vol. 21, no. 9, September 2009. – P. 1263-1284.
- Паклин Н.Б., Орешков В.И. Бизнес-аналитика: от данных к знаниям (+CD): Учеб. Пособие. 2-е изд., перераб. и доп. – СПб.: Питер, 2010. – 704 с.: ил.