
Обычно, когда говорят о серьезной аналитической обработке, особенно если используют термин Data Mining, подразумевают, что данных огромное количество. В общем случае это не так, т. к. довольно часто приходится обрабатывать небольшие наборы данных, и находить в них закономерности ничуть не проще, чем в сотнях миллионов записей. Хотя нет сомнений, что необходимость поиска закономерностей в больших базах данных усложняет и без того нетривиальную задачу анализа.
Такая ситуация особенно характерна для бизнеса, связанного с розничной торговлей, телекоммуникациями, банками, интернетом. В их базах данных аккумулируется огромное количество информации, связанной с транзакциями: чеки, платежи, звонки, логи и т.п.
Не существует универсальных способов анализа или алгоритмов, пригодных для любых случаев и любых объемов информации. Методы анализа данных существенно отличаются друг от друга по производительности, качеству результатов, удобству применения и требованиям к данным. Оптимизация может производиться на различных уровнях: оборудование, базы данных, аналитическая платформа, подготовка исходных данных, специализированные алгоритмы. Анализ большого объема данных требует особого подхода, т.к. технически сложно их переработать при помощи только "грубой силы", т.е. использования более мощного оборудования.
Конечно, можно увеличить скорость обработки данных за счет более производительного оборудования, тем более, что современные сервера и рабочие станции используют многоядерные процессоры, оперативную память значительных размеров и мощные дисковые массивы. Однако, есть множество других способов обработки больших объемов данных, которые позволяют повысить масштабируемость и не требуют бесконечного обновления оборудования.
Возможности СУБД
Современные базы данных включают различные механизмы, применение которых позволит значительно увеличить скорость аналитической обработки:
- Предварительный обсчет данных. Сведения, которые чаще всего используются для анализа, можно заранее обсчитать (например, ночью) и в подготовленном для обработки виде хранить на сервере БД в виде многомерных кубов, материализованных представлений, специальных таблиц.
- Кэширование таблиц в оперативную память. Данные, которые занимают немного места, но к которым часто происходит обращение в процессе анализа, например, справочники, можно средствами базы данных кэшировать в оперативную память. Так во много раз сокращаются обращения к более медленной дисковой подсистеме.
- Разбиение таблиц на разделы и табличные пространства. Можно размещать на отдельных дисках данные, индексы, вспомогательные таблицы. Это позволит СУБД параллельно считывать и записывать информацию на диски. Кроме того, таблицы могут быть разбиты на разделы (partition) таким образом, чтобы при обращении к данным было минимальное количество операций с дисками. Например, если чаще всего мы анализируем данные за последний месяц, то можно логически использовать одну таблицу с историческими данными, но физически разбить ее на несколько разделов, чтобы при обращении к месячным данным считывался небольшой раздел и не было обращений ко всем историческим данным.
Это только часть возможностей, которые предоставляют современные СУБД. Повысить скорость извлечения информации из базы данных можно и десятком других способов: рациональное индексирование, построение планов запросов, параллельная обработка SQL запросов, применение кластеров, подготовка анализируемых данных при помощи хранимых процедур и триггеров на стороне сервера БД и т.п. Причем многие из этих механизмов можно использовать с применением не только "тяжелых" СУБД, но и бесплатных баз данных.
Комбинирование моделей
Возможности повышения скорости не сводятся только к оптимизации работы базы данных, многое можно сделать при помощи комбинирования различных моделей. Известно, что скорость обработки существенно связана со сложностью используемого математического аппарата. Чем более простые механизмы анализа используются, тем быстрее данные анализируются.
Возможно построение сценария обработки данных таким образом, чтобы данные "прогонялись" через сито моделей. Тут применяется простая идея: не тратить время на обработку того, что можно не анализировать.
Вначале используются наиболее простые алгоритмы. Часть данных, которые можно обработать при помощи таких алгоритмов и которые бессмысленно обрабатывать с использованием более сложных методов, анализируется и исключается из дальнейшей обработки. Оставшиеся данные передаются на следующий этап обработки, где используются более сложные алгоритмы, и так далее по цепочке. На последнем узле сценария обработки применяются самые сложные алгоритмы, но объем анализируемых данных во много раз меньше первоначальной выборки. В результате общее время, необходимое для обработки всех данных, уменьшается на порядки.
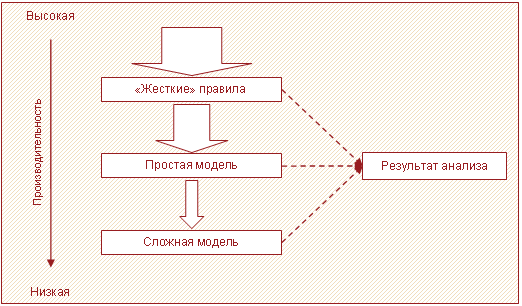
Приведем практический пример использования этого подхода. При решении задачи прогнозирования спроса первоначально рекомендуется провести XYZ-анализ, который позволяет определить, насколько стабилен спрос на различные товары. Товары группы X продаются достаточно стабильно, поэтому применение к ним алгоритмов прогнозирования позволяет получить качественный прогноз. Товары группы Y продаются менее стабильно, возможно для них стоит строить модели не для каждого артикула, а для группы, это позволяет сгладить временной ряд и обеспечить работу алгоритма прогнозирования. Товары группы Z продаются хаотично, поэтому для них вообще не стоит строить прогностические модели, потребность в них нужно рассчитывать на основе простых формул, например, среднемесячных продаж.
По статистике около 70 % ассортимента составляют товары группы Z. Еще около 25 % - товары группы Y и только примерно 5 % - товары группы X. Таким образом, построение и применение сложных моделей актуально максимум для 30 % товаров. Поэтому применение описанного выше подхода позволит сократить время на анализ и прогнозирование в 5-10 раз.
Параллельная обработка
Еще одной эффективной стратегией обработки больших объемов данных является разбиение данных на сегменты и построение моделей для каждого сегмента по отдельности, с дальнейшим объединением результатов. Чаще всего в больших объемах данных можно выделить несколько отличающихся друг от друга подмножеств. Это могут быть, например, группы клиентов, товаров, которые ведут себя схожим образом и для которых целесообразно строить одну модель.
В этом случае вместо построения одной сложной модели для всех можно строить несколько простых для каждого сегмента. Подобный подход позволяет повысить скорость анализа и снизить требования к памяти благодаря обработке меньших объемов данных в один проход. Кроме того, в этом случае аналитическую обработку можно распараллелить, что тоже положительно сказывается на затраченном времени. К тому же модели для каждого сегмента могут строить различные аналитики.
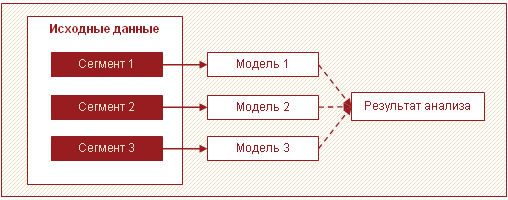
Помимо повышения скорости этот подход имеет и еще одно важное преимущество – несколько относительно простых моделей по отдельности легче создавать и поддерживать, чем одну большую. Можно запускать модели поэтапно, получая таким образом первые результаты в максимально сжатые сроки.
Репрезентативные выборки
При наличии больших объемов данных можно использовать для построения модели не всю информацию, а некоторое подмножество – репрезентативную выборку. Корректным образом подготовленная репрезентативная выборка содержит в себе информацию, необходимую для построения качественной модели.
Процесс аналитической обработки делится на 2 части: построение модели и применение построенной модели к новым данным. Построение сложной модели – ресурсоемкий процесс. В зависимости от применяемого алгоритма данные кэшируются, сканируются тысячи раз, рассчитывается множество вспомогательных параметров и т.п. Применение же уже построенной модели к новым данным требует ресурсов в десятки и сотни раз меньше. Очень часто это сводится к вычислению нескольких простых функций.
Таким образом, если модель будет строиться на относительно небольших множествах и применяться в дальнейшем ко всему набору данных, то время получения результата сократится на порядки по сравнению с попыткой полностью переработать весь имеющийся набор данных.
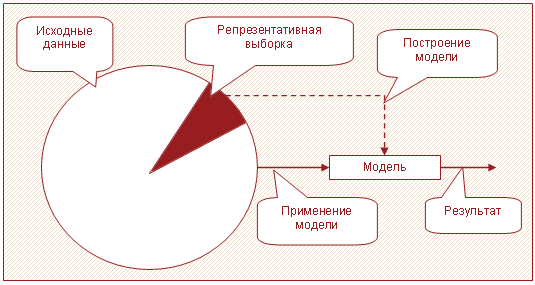
Для получения репрезентативных выборок существуют специальные методы, например, сэмплинг. Их применение позволяет повышать скорость аналитической обработки, не жертвуя качеством анализа.
Резюме
Описанные подходы – это только небольшая часть методов, которые позволяют анализировать огромные объемы данных. Существуют и другие способы, например, применение специальных масштабируемых алгоритмов, иерархических моделей, обучение окнами и прочее.
Анализ огромных баз данных – это нетривиальная задача, которая в большинстве случаев не решается "в лоб", однако современные базы данных и аналитические платформы предлагают множество методов решения этой задачи. При разумном их применении системы способны перерабатывать терабайты данных с приемлемой скоростью.