Нечеткие запросы к реляционным базам данных
Введение
Механизмы нечетких запросов (fuzzy queries, flexible queries) к реляционным базам данных базирующиеся на теории нечетких множеств Заде, были впервые предложены в 1984 году и впоследствии получили развитие в работах Д. Дюбуа и Г. Прада.
Для чего это необходимо
Большая часть данных, обрабатываемых в современных информационных системах, носят четкий, числовой характер. Однако в запросах к базам данных, которые пытается формулировать человек, часто присутствуют неточности и неопределенности. Не удивительно, когда на запрос в поисковой системе Интернета пользователю выдается множество ссылок на документы, упорядоченных по степени релевантности (или соответствия) запросу. Потому что текстовой информации изначально присуща нечеткость и неопределенность, причинами которой является семантическая неоднозначность языка, наличие синонимов и т.д.
С базами данных информационных систем, или с четкими базами данных (Crisp Databases) ситуация другая. Пусть, например, из базы данных требуется извлечь следующую информацию:
- "Получить список молодых сотрудников с невысокой заработной платой"
- "Найти предложения о сдаче не очень дорогого жилья близко к центру города"
Здесь высказывания "Молодой", "Невысокая", "Не очень дорогой", "Близко" имеют размытый, неточный характер, хотя заработная плата определена до рубля, а удаленность квартиры от центра – с точностью до километра. Причиной всему служит то, что в реальной жизни мы оперируем и рассуждаем неопределенными, неточными категориями. Такие запросы невозможно выполнить средствами языка SQL. И на помощь приходит концепция нечетких запросов.
Продемонстрируем ограниченность четких запросов на следующем примере. Пусть требуется получить сведения о менеджерах по продажам не старше 25 лет, у которых сумма годовых сделок превысила 200 тыс. по такому-то региону. Данный запрос можно записать на языке SQL следующим образом:
select FIO from Managers
where (Managers.Age <= 25 AND Managers.Sum > 200000 AND Managers.RegionID = 1)
Менеджер по продажам 26 лет с годовой суммой продаж в 400 тыс., или 19 лет с суммой в 198 тыс. не попадут в результат запроса, хотя их характеристики почти удовлетворяют требованиям запроса.
Нечеткие запросы помогают справиться с подобными проблемами "пропадания" информации.
Как это работает
Механизм работы нечетких запросов основан на теории нечетких множеств, основные сведения из которой изложены в предыдущей статье Нечеткая логика – математические основы.
Рассмотрим наиболее распространенные способы генерации новых лингвистических термов на основе базового терм-множества. Это полезно для построения разнообразных семантических конструкций, которые усиливают или ослабляют высказывания, например: "очень высокая цена", "приблизительно среднего возраста" и т.д. Для этого существуют лингвистические модификаторы (linguistic hedges), усиливающие или ослабляющие высказывание. К усиливающим относится модификатор "Очень" (Very), к ослабляющим – "Более-или-менее", или "Приблизительно", "Почти" (more-or-less), нечеткие множества которых описываются функциями принадлежности вида:
$${2,5} MF_{VERY}\,(X) = {(MF\,(X))}^2$$
$$MF_{MORE-OR-LESS}\,(X) = \sqrt{MF\,(X)}$$
Для примера формализуем нечеткое понятие "Возраст сотрудника компании". Это и будет название соответствующей лингвистической переменной. Зададим для нее область определения X = [18; 70] и три лингвистических терма – "Молодой", "Средний", "Выше среднего". Последнее, что осталось сделать – построить фунции принадлежности для каждого лингвистического терма.
Выберем трапецеидальные функции принадлежности со следующими координатами:
"Молодой" = [18, 18, 28, 34], "Средний" = [28, 35, 45, 50], "Выше среднего" = [42, 53, 60, 60].
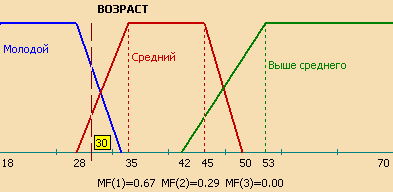
Теперь можно вычислить степень принадлежности сотрудника 30 лет к каждому из нечетких множеств:
MF[Молодой](30)=0,67; MF[Средний](30)=0,29; MF[Выше среднего](30)=0.
Основное требование при построении функций принадлежности – значение функций принадлежности должно быть больше нуля хотя бы для одного лингвистического терма.
В заключение определим операцию нечеткого отрицания (NOT): MF[NOT](X)=1-MF(X).
Приведенных выше сведений достаточно для построения и выполнения нечетких запросов.
Вернемся к примеру с менеджерами о продажах. Для простоты предположим, что вся необходимая информация находятся в одной таблице со следующими полями: ID – номер сотрудника, AGE – возраст и SUM (годовая сумма сделок).
| ID | AGE | SUM |
|---|---|---|
| 1 | 23 | 120 500 |
| 2 | 25 | 164 000 |
| 3 | 28 | 398 000 |
| 4 | 31 | 489 700 |
| 5 | 33 | 251 900 |
| … | ||
Лингвистическая переменная "Возраст" была задана ранее. Определим еще одну лингвистическую переменную для поля SUM с областью определения X = [0; 600000] и термами "Малая", "Средняя" и "Большая" и аналогично построим для них функции принадлежности:
"Малая" = [0, 0, 0, 200000], "Средняя" = [90000, 180000, 265000, 330000], "Большая" = [300000, 420000, 600000, 600000].
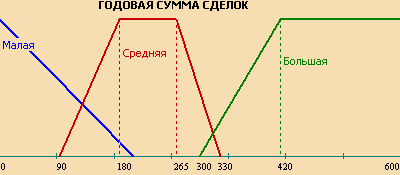
К такой таблице можно делать нечеткие запросы. Например, получить список всех молодых менеджеров по продажам с большой годовой суммой сделок, что на SQL-подобном синтаксисе запишется так:
select * from Managers where (Age = "Молодой" AND Sum = "Большая")
Рассчитав для каждой записи агрегированное значение функции принадлежности MF (при помощи операции нечетого "И"), получим результат нечеткого запроса:
| ID | AGE | SUM | MF |
|---|---|---|---|
| 3 | 28 | 398 000 | 0,82 |
| 4 | 31 | 489 700 | 0,50 |
Записи 1,2,5 не попали в результат запроса, т.к. для них значение функции принадлежности равно нулю. Записей, точно удовлетворяющих поставленному запросу (MF=1), в таблице не нашлось. Менеджер по продажам 28 лет и годовой суммой 398000 соответствует запросу с функцией принадлежности 0,82. На практике обычно вводят пороговое значение функции принадлежности, при превышении которого записи включаются в результат нечеткого запроса.
Аналогичный четкий запрос мог бы быть сформулирован, например, так:
select * from Managers where (Age <= 28 AND Sum >= 420000)
Его результат является пустым. Однако если мы немного расширим рамки возраста в запросе, то рискуем упустить других сотрудников с чуть более большим или меньшим возрастом. Поэтому можно сказать, что нечеткие запросы позволяют расширить область поиска в соответствии с изначально заданными человеком ограничениями.
Используя нечеткие модификаторы, можно формировать и более сложные запросы:
select * from Managers where (Age = "Более-или-менее Средний" AND Sum = "Средняя")
Результат:
| ID | AGE | SUM | MF |
|---|---|---|---|
| 5 | 33 | 251 900 | 0,85 |
Часто требуется оперировать не лингвистическими переменными, а нечеткими аналогами точных значений. Для этого существует нечеткое отношение "ОКОЛО" (Например, "Цена около 20"). Для реализации подобных нечетких отношений аналогично строится нечеткое множество с соответствующей функцией принадлежности, но уже на некотором относительном интервале (например, [-5; 5]) для избежания зависимости от контекста. При вычислении функции принадлежности нечеткого отношения "Около Q" (Q – некоторое четкое число) производят масштабирование на относительный интервал.
Проиллюстрируем вышесказанное на примере таблицы с данными о ценных бумагах. Пусть она имеет в своем составе следующие поля: PRICE (стоимость ценной бумаги), RATIO (отношение цены к прибыли, price-to-earnings ratio), AYIELD (усредненный доход за последний квартал, average yield, %).
| ID | PRICE | RATIO | AYIELD |
|---|---|---|---|
| 1 | 260 | 11 | 15,0 |
| 2 | 380 | 5 | 7,0 |
| 3 | 810 | 6 | 10,0 |
| 4 | 110 | 9 | 14,0 |
| 5 | 420 | 10 | 16,0 |
Пусть требуется найти ценные бумаги для покупки не дороже $150, с доходностью 15% и отношением цены прибыли 11. Это эквивалентно следующему SQL-запросу:
select * FROM some_table where ((PRICE<=150) AND (RATIO=11) AND (AYIELD=15))
Результат такого запроса будет пустым.
Тогда сформулируем этот же запрос в нечетком виде с использованием отношения "ОКОЛО":
select * FROM some_table
where ((PRICE = "Около 150") AND (RATIO= "Около 11") AND (AYIELD="Около 15"))
Построим нечеткое множество для отношения "ОКОЛО" в относительном интервале [-5; 5]. Это будет трапеция с координатами [-2, -1, 1, 2].
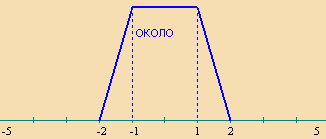
Рассчитаем значение нечеткого запроса "Цена около 250" для цены 380. Предварительно зададим области определения каждой лингвистической переменной: PRICE – [0; 1000], RATIO – [0; 20], AYIELD – [0; 20]. Значение 130 (полученное как разница между 380 и 250) отмасштабируем на интервал [-5; 5], получим величину x=1,3 и MF(1,3)=0,7.
Применив нечеткое отношение ОКОЛО к каждому полю PRICE, RATIO и AYIELD и рассчитав агрегированное значение функции принадлежности с помощью операции нечеткое "И", получим следующий результат запроса.
| ID | PRICE | RATIO | AYIELD | MF |
|---|---|---|---|---|
| 1 | 260 | 11 | 15,0 | 1 |
| 4 | 110 | 9 | 14,0 | 0,9 |
Недостатком нечетких запросов является относительная субъективность функций принадлежности.
Области применения нечетких запросов
Нечеткие запросы перспективно использовать в областях, где осуществляется выбор информации из баз данных с использованием качественных критериев и нечетко сформулированных условий, например, Direct Marketing.
В прямом маркетинге очень важен этап выделения целевой аудитории, для которой будут применяться различные инструменты direct marketing. Например, это прямая почтовая реклама (direct mail), используемая при продвижении товаров и услуг организациям и частным лицам. Однако для получения максимального эффекта от direct mail необходим тщательный выбор адресатов. Если отбор адресатов будет либеральным, то возрастут неоправданные расходы на прямой маркетинг, если слишком строгим – будет потерян ряд потенциальных клиентов.
Например, компания проводит рекламную акцию среди своих клиентов о новых услугах с помощью прямой почтовой рассылки. Служба маркетинга установила, что наиболее интересен новый вид услуги будет мужчинам средних лет, отцам семейств с годовым доходом выше среднего. Для получения списка адресатов к базе данных клиентов, скорее всего, будет сделан следующий запрос: выбрать всех лиц мужского пола в возрасте от 40 до 55 лет, имеющих минимум 1 ребенка, годовой доход от 20 до 30 тысяч долл. Такие точные критерии запроса могут отсеять множество потенциальных клиентов: мужчина 39 лет, отец троих детей с доходом в 31 тысячу не попадет в результат запроса, хотя это потенциальный потребитель новой услуги.
Аналогичным образом нечеткие запросы можно использовать при выборе туристических услуг, подборе объектов недвижимости.
Инструмент нечетких запросов позволяет согласовать формальные критерии и неформальные требования к кругу потенциальных клиентов и задавать интервалы выбора потенциальных клиентов как нечеткие множества. В таком случае клиенты, не удовлетворяющие какому-то одному критерию, могут быть выбраны из базы данных, если они имеют хорошие показатели по другим критериям.
- Дюбуа Д., Прад Г. Теория возможностей. Приложения к представлению знаний в информатике – М.: Радио и связь, 1990.
- Ribeiro R.A., Moreira A.M. Fuzzy Query Interface for a Business Database // International Journal of Human-Computers Studies, Vol. 58 (2003), PP. 363-391.
- Dubois D., Prade H. Using Fuzzy Sets in Database Systems: Why and How? // Proc. of 1996 Workshop on Flexible Query-Answering systems (FQAS'96), Denmark, May 22-24, 1996, PP. 89-103.
- Смолко Д.С.,Черноруцкий И.Г. Система поддержки принятия решения для портфеля ценных бумаг // Сборник докладов I Международной конференции по мягким вычислениям и измерениям (SCM-98), Санкт-Петербург, 1998, том 2, С. 231-234.
