
Введение
Человек, сталкиваясь с новой задачей, использует свой жизненный опыт, вспоминает аналогичные ситуации, которые когда-то с ним происходили. О свойствах нового объекта мы судим, полагаясь на похожие знакомые наблюдения. Например, встретив иностранца на улице, мы можем догадаться о его происхождении по речи, жестам и внешности. Для этого необходимо вспомнить наиболее похожего человека на него, происхождение которого известно.
Так, подобно приведенному выше примеру, сходство объектов лежит в основе алгоритма k-ближайших соседей (k-nearest neighbor algorithm, KNN). Алгоритм способен выделить среди всех наблюдений k известных объектов (k-ближайших соседей), похожих на новый неизвестный ранее объект. На основе классов ближайших соседей выносится решение касательно нового объекта. Важной задачей данного алгоритма является подбор коэффициента k – количество записей, которые будут считаться близкими.
Алгоритм KNN широко применяется в Data Mining.
Алгоритм KNN
Рассмотрим задачу классификации.
Пусть имеется m наблюдений, каждому из которых соответствует запись в таблице. Все записи принадлежат какому-либо классу. Необходимо определить класс для новой записи.
На первом шаге алгоритма следует задать число k – количество ближайших соседей. Если принять k = 1, то алгоритм потеряет обобщающую способность (то есть способность выдавать правильный результат для данных, не встречавшихся ранее в алгоритме) так как новой записи будет присвоен класс самой близкой к ней. Если установить слишком большое значение, то многие локальные особенности не будут выявлены.
На втором шаге находятся k записей с минимальным расстоянием до вектора признаков нового объекта (поиск соседей). Функция для расчета расстояния должна отвечать следующим правилам:
- d(x,y) ≥ 0, d(x,y) = 0 тогда и только тогда, когда x = y;
- d(x,y) = d(y,x);
- d(x,z) ≤ d(x,y) + d(y,z), при условии, что точки x, y, z не лежат на одной прямой.
Где x, y, z - векторы признаков сравниваемых объектов.
Для упорядоченных значений атрибутов находится Евклидово расстояние:
$D_E = \sqrt{\sum \limits_{i}^{n}(x_i\,-\,y_i)^2}$,
где n – количество атрибутов.
Для строковых переменных, которые не могут быть упорядочены, может быть применена функция отличия, которая задается следующим образом:
$dd\,(x,\,y)= \begin{cases} 0, \ x=y \\ 1, \ x\neq y \end{cases} $.
Часто перед расчетом расстояния необходима нормализация. Приведем некоторые полезные формулы.
Минимаксная нормализация:
$X^\times = \frac{X\,-\,\min \,\bigl(X\bigr )}{\max \,\bigl(X\bigr )\,-\,\min \,\bigl(X\bigr )}$.
Нормализация с помощью стандартного отклонения:
$X^\times = \frac{X\,-\,X_{cp}}{\sigma_x}$,
где $\sigma_x$ – стандартное отклонение, Xср – среднее значение.
При нахождении расстояния иногда учитывают значимость атрибутов. Она определяется экспертом или аналитиком субъективно, полагаясь на собственный опыт. В таком случае при нахождении расстояния каждый i-ый квадрат разности в сумме умножается на коэффициент Zi. Например, если атрибут A в три раза важнее атрибута B (ZA = 3, ZB = 1), то расстояние будет находиться следующим образом:
$D_E = \sqrt{3 (x_A\,-\,y_A)^2\,+\,(x_B\,-\,y_B)^2}$.
Подобный прием называют растяжением осей (stretching the axes), что позволяет снизить ошибку классификации.
Следует отметить, что если для записи B ближайшем соседом является А, то это не означает, что В – ближайший сосед А. Данная ситуация представлена на рисунке 1. При k = 1 ближайшей для точки B будет точка A, а для A – X. При увеличении коэффициента до k = 7, точка B так же не будет входить в число соседей.

На следующем шаге, когда найдены записи, наиболее похожие на новую, необходимо решить, как они влияют на класс новой записи. Для этого используется функция сочетания (combination function). Одним из основных вариантов такой функции является простое невзвешенное голосование (simple unweighted voting).
Простое невзвешенное голосование
Вначале, задав число k, мы определили, сколько записей будет иметь право голоса при определении класса. Затем мы выявили эти записи, расстояние от которых до новой оказалось минимальным. Теперь можно приступить к простому невзвешенному голосованию.
Расстояние от каждой записи при голосовании здесь больше не играет роли. Все имеют равные права в определении класса. Каждая имеющаяся запись голосует за класс, к которому принадлежит. Новой записи присваивается класс, набравший наибольшее количество голосов.
Но что делать в случае, если несколько классов набрали равное количество голосов? Эту проблему снимает взвешенное голосование (weighted voting).
Взвешенное голосование
В такой ситуации учитывается также и расстояние до новой записи. Чем меньше расстояние, тем более значимый вклад вносит голос. Голоса за класс находятся по следующей формуле:
$votes\,(class) = \sum\limits_{i=1}^{n}\frac{1}{d^2\,(X,\,Y_i )}$,
где d2(X, Yi) – квадрат расстояния от известной записи Yi до новой X, n – количество известных записей класса, для которого рассчитываются голоса, class - наименование класса.
Новая запись соотносится с классом, набравшим наибольшее количество голосов. При этом вероятность того, что несколько классов наберут одинаковые голоса, гораздо ниже. Совершенно очевидно, что при k = 1 новой записи присваивается класс самого ближайшего соседа.
Примеры работы алгоритма KNN
Решим задачу классификации для ирисов (используя данные об ирисах Фишера, которые доступны по ссылке [1]). Имеется набор данных, собранных Р. Фишером, о 150 цветках трех классов: Iris Setosa, Iris Versicolour, Iris Virginica, по 50 записей для каждого. Известна длина и ширина чашелистика и лепестка всех этих ирисов.
Для простоты рассмотрим только два входных поля: длина чашелистика и длина лепестка, а также выходное – класс цветка.
Необходимо определить класс двух цветков со следующими значениями длины чашелистика и лепестка в сантиметрах: 5,3 и 1,6 (первый), 6,1 и 4,8 (второй). На рисунке 2 показано размещение новых (светло-зеленая точка – цветок 1, красная – цветок 2) записей среди уже известных.
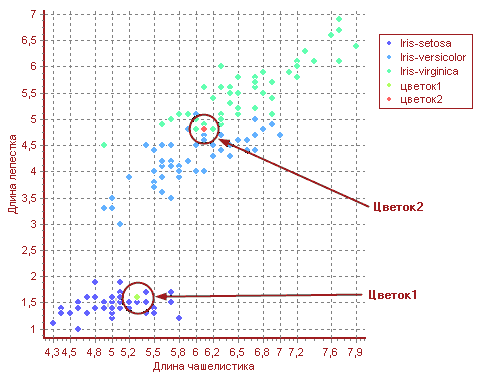
Рассмотрим первый цветок. Установим значение k = 3. Таким образом, необходимо найти трех ближайших соседей. Для первого цветка это будут цветки со следующими значениями длины чашелистика и лепестка: A (5,3; 1,5), В(5,2; 1,5) и С(5,2; 1,5). Покажем, чему равны расстояния до первого цветка (оба атрибута равнозначны):
d(цветок1, A) $= \sqrt{{\bigl(5,3\,-\,5,3\bigr)}^2\,+\,{\bigl(1,6\,-\,1,5\bigr)}^2 } = \sqrt{0\,+\,0,01 } = 0,1$
d(цветок1, В) $ = \sqrt{{\bigl(5,3\,-\,5,2\bigr)}^2\,+\,{\bigl(1,6\,-\,1,5\bigr)}^2 } = \sqrt{0,01\,+\,0,01 } = 0,141421356$
d(цветок1, C) $= \sqrt{{\bigl(5,3\,-\,5,2\bigr)}^2\,+\,{\bigl(1,6\,-\,1,5\bigr)}^2 } = \sqrt{0,01\,+\,0,01 } = 0,141421356$
Полученные сведения объединим в таблицу 1.
Таблица 1 – 3 ближайших соседа для цветка 1
| Запись | Длина чашелистика | Длина лепестка | Расстояние | Класс |
|---|---|---|---|---|
| Цветок 1 | 5,3 |
1,6 |
– |
– |
| A | 5,3 |
1,5 |
0,1 |
Iris-Setosa |
| B | 5,2 |
1,5 |
0,14 |
Iris-Setosa |
| C | 5,2 |
1,5 |
0,14 |
Iris-Setosa |
Теперь определим класс нового цветка. Воспользуемся простым невзвешенным голосованием. Так как все три цветка A, B и C принадлежат к классу Iris-Setosa, то он получает 100% голосов, и первому цветку присваиваем этот класс. Если увеличить (рисунок 3) на диаграмме окрестность около первого цветка, то можно увидеть, что он окружен точками синего цвета, соответствующие цветам класса Iris-Setosa.
Теперь рассмотрим более сложный случай cо вторым цветком.
Зададим k = 3 и предположим, что длина лепестка вдвое важнее длины чашелистика. Ближайшими тремя соседями будут следующие цветки:
A(6,1; 4,7), B(6; 4,8), C(6,2 4,8)
Покажем, чему для них равны расстояния:
d(цветок2, A)$= \sqrt{{\bigl(6,1\,-\,6,1\bigr)}^2\,+\,2\,{\bigl(4,8\,-\,4,7\bigr)}^2 } = \sqrt{0,02 } = 0,141421356$
d(цветок2, B)$= \sqrt{{\bigl(6,1\,-\,6\bigr)}^2\,+\,2\,{\bigl(4,8\,-\,4,8\bigr)}^2 } = \sqrt{0,01 } = 0,1$
d(цветок2, C)$= \sqrt{{\bigl(6,1\,-\,6,2\bigr)}^2\,+\,2\,{\bigl(4,8\,-\,4,8\bigr)}^2 } = \sqrt{0,01 } = 0,1$
В и С – это Iris Virginica, а A – Iris Versicolour.
Объединим полученные сведения в таблицу 2.
Таблица 2 – Три ближайших соседа для цветка 2
| Запись | Длина чашелистика | Длина лепестка | Расстояние | Класс |
|---|---|---|---|---|
| Цветок 2 | 6,1 |
4,8 |
– |
– |
| A | 6,1 |
4,7 |
0,14 |
Iris Versicolour |
| B | 6 |
4,8 |
0,1 |
Iris Virginica |
| C | 6,2 |
4,8 |
0,1 |
Iris Virginica |
Рассмотрим взвешенное голосование.
$Votes\,\bigl(IrisVersicolour\bigr) = \frac{1}{{\Bigl(\sqrt{0,02}\Bigr)}^2} = \frac{1}{0,02} = 50$
$Votes\,\bigl(IrisVirginica\bigr) = \frac{1}{0,1^2}\,+\, \frac{1}{0,1^2} = \frac{2}{0,01} = 200$
Так как 200>50, то второй цветок классифицируется как Iris Virginica.
Области применения алгоритма KNN
Алгоритм k-ближайших соседей имеет широкое применение. Например:
- Обнаружение мошенничества. Новые случаи мошенничества могут быть похожи на те, которые происходили когда-то в прошлом. Алгоритм KNN может распознать их для дальнейшего рассмотрения.
- Предсказание отклика клиентов. Можно определить отклик новых клиентов по данным из прошлого.
- Медицина. Алгоритм может классифицировать пациентов по разным показателям, основываясь на данных прошедших периодов.
- Прочие задачи, требующие классификацию.
В заключение отметим достоинства и недостатки алгоритма KNN.
Перечислим положительные особенности.
- Алгоритм устойчив к аномальным выбросам, так как вероятность попадания такой записи в число k-ближайших соседей мала. Если же это произошло, то влияние на голосование (особенно взвешенное) (при k>2) также, скорее всего, будет незначительным, и, следовательно, малым будет и влияние на итог классификации.
- Программная реализация алгоритма относительно проста.
- Результат работы алгоритма легко поддаётся интерпретации. Экспертам в различных областях вполне понятна логика работы алгоритма, основанная на нахождении схожих объектов.
- Возможность модификации алгоритма, путём использования наиболее подходящих функций сочетания и метрик позволяет подстроить алгоритм под конкретную задачу.
Алгоритм KNN обладает и рядом недостатков. Во-первых, набор данных, используемый для алгоритма, должен быть репрезентативным. Во-вторых, модель нельзя "отделить" от данных: для классификации нового примера нужно использовать все примеры. Эта особенность сильно ограничивает использование алгоритма
- Berry, Michael J. A. “Data mining techniques: for marketing, sales, and customer relationship management “/ Michael J.A. Berry, Gordon Linoff. – 2nd ed.
- Larose, Daniel T. “Discovering knowledge in data: an introduction to data mining” / Daniel T. Larose