
Архитектура ансамбля моделей
Кафедра «Информатики и программного обеспечения» Брянского государственного технического университета [1] приняла участие в проекте по мониторингу наркоситуации в Брянской области, который проводится ежегодно по заказу УФСКН РФ по Брянской области кафедрой социально-гуманитарных дисциплин [2] Брянского филиала Российской академии народного хозяйства и государственной службы. Целью проекта является анализ и оценка состояния наркоситуации в Брянской области.
С описанием задачи и информацией об исходных данных можно познакомиться в первой части статьи [3].
Для построения полноценного ансамбля моделей необходимо выполнить следующие три этапа:
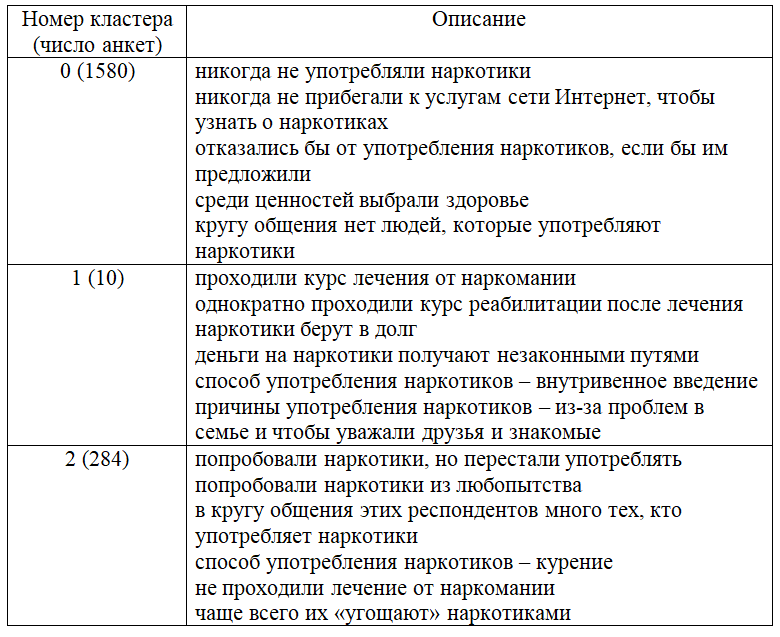
- Алгоритм кластеризации CLOPE хорошо работает с транзакционными данными. На этом этапе пока можно не указывать желаемое количество кластеров, а посмотреть, сколько их получится. Если их получится достаточно много, и большинство кластеров будет содержать малое количество транзакций, то необходимо запустить алгоритм снова, и указать желаемое количество кластеров. После этого можно переходить к следующему этапу построения ансамбля моделей – к деревьям решений.
- В качестве входных данных для деревьев решений необходимо использовать данные, полученные на первом шаге алгоритмом CLOPE, которые представляют собой таблицу записей, с добавлением номера кластера. Деревья решений позволят аналитику увидеть, по каким именно признакам (по каким вопросам и ответам), анкеты попадают в тот или иной кластер.
- Третьим этапом построения ансамбля моделей является применение ассоциативных правил. Они нужны для того, чтобы посмотреть какие именно зависимости и связи между признаками имеются в социологических данных. Это позволит провести комплексный анализ, увидеть картину с разных сторон, которые будут дополнять друг друга, и сделать правильные выводы.
Выполнение трех предложенных этапов в формировании ансамбля моделей позволит повысить точность анализа социологических данных и качество этого анализа. Графически схема построения ансамбля моделей показана на рисунке 1.
 [4]
[4]
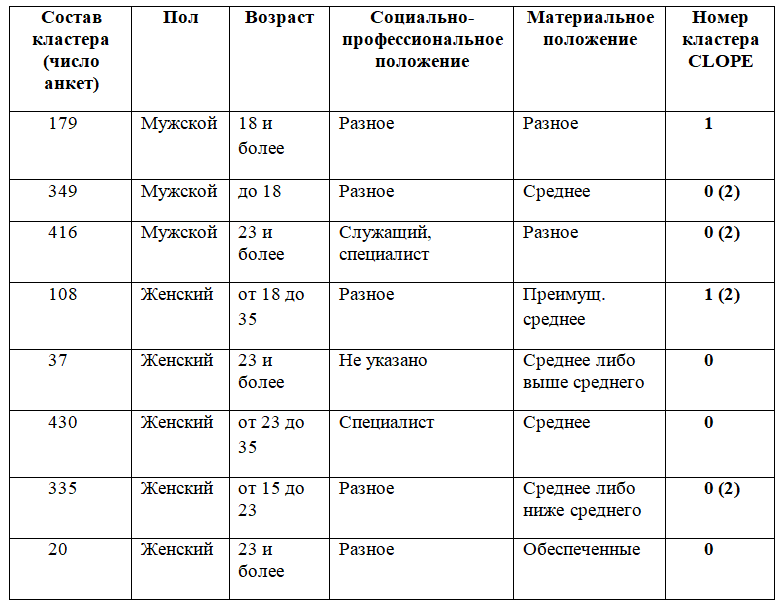
Итоги анализа представлены на рисунках 2, 3, 4.
 [5]
[5]
|
 [6]
[6]
|
 [7]
[7]
|
Скоринговые модели
В исходной выборке содержалось 4043 анкеты за 2013-2014 годы. После этапа очистки и предобработки данных 3 анкеты ушли. Далее применялся сэмплинг (методом отбора со смещением) для формирования обучающей выборки для скоринговой модели. В нее попало 1002 анкеты по 501 анкете каждого класса (группа риска, не группа риска). Кластеризация проводилась ранее методом CLOPE.
Далее этап определения конечных классов (производилось только квантование возраста). Далее в сценарий включалась логистическая регрессия. И последний этап – классификация анкет на основе скоринговой модели, структура показана на рисунке 5.
 [8]
[8]
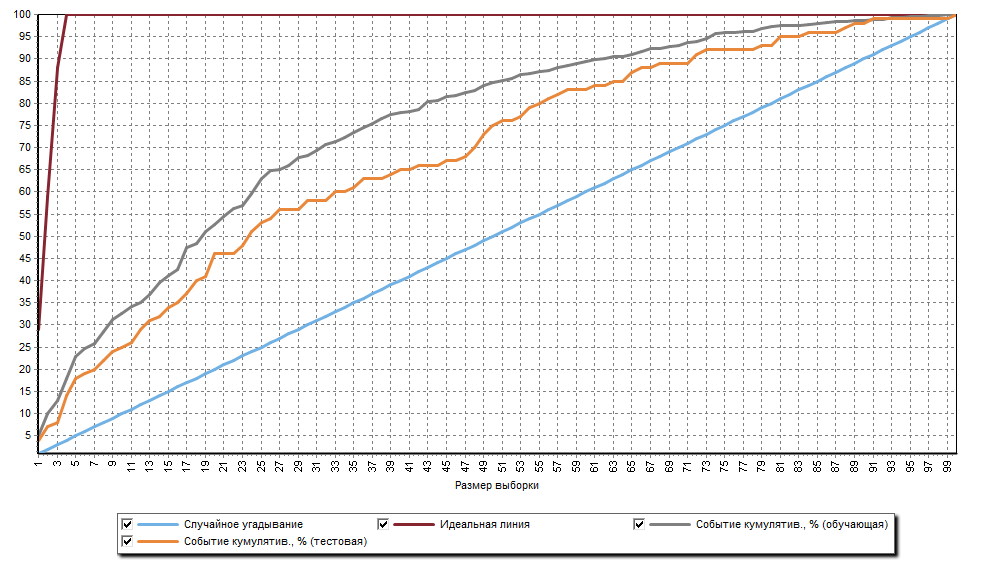
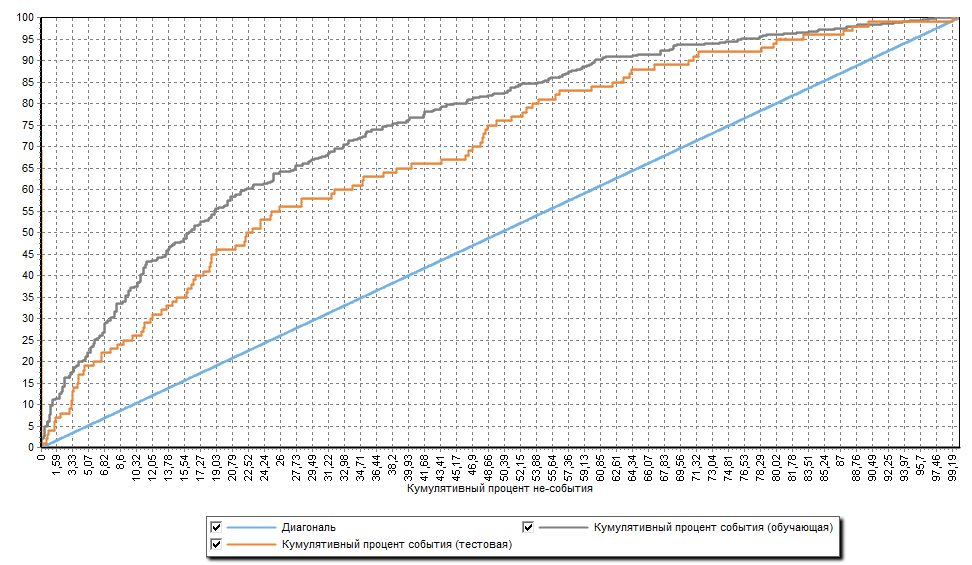
Было построено четыре скоринговые модели, которые отличались методом отбора переменных. Для каждой модели были построены ROC-кривые, CAP-кривые и диаграммы, отражающие шансы события/не-события (рисунки 6, 7 и 8). Выбрана скоринговая модель с лучшими показателями (метод отбора переменных – прямой отбор). Эта скоринговая модель используется в сценарии Deductor Enterprise в качестве рабочей модели.
 [9]
[9]
|
 [10]
[10]
|
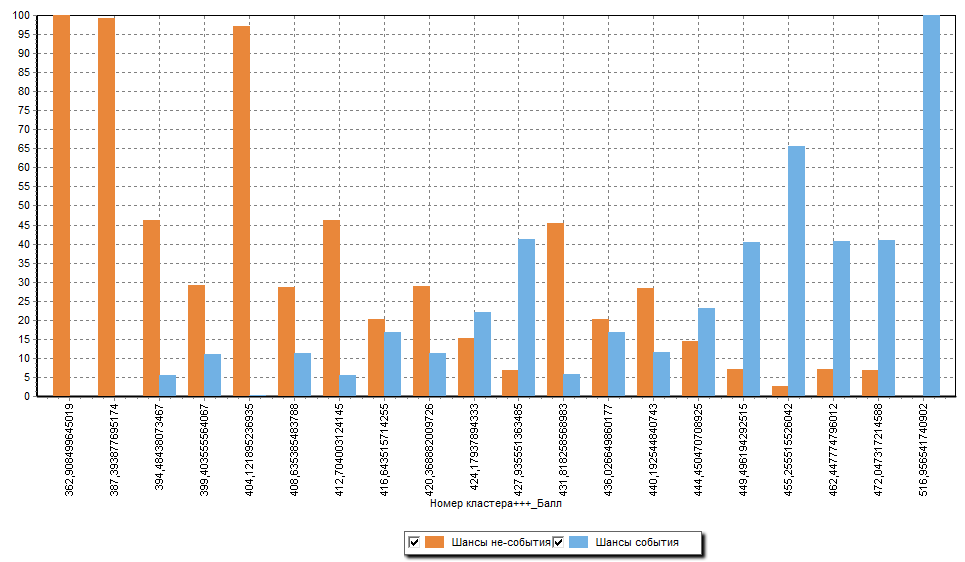 [11]
[11]
Руководитель проекта
Лагерев Дмитрий
к.т.н., доцент